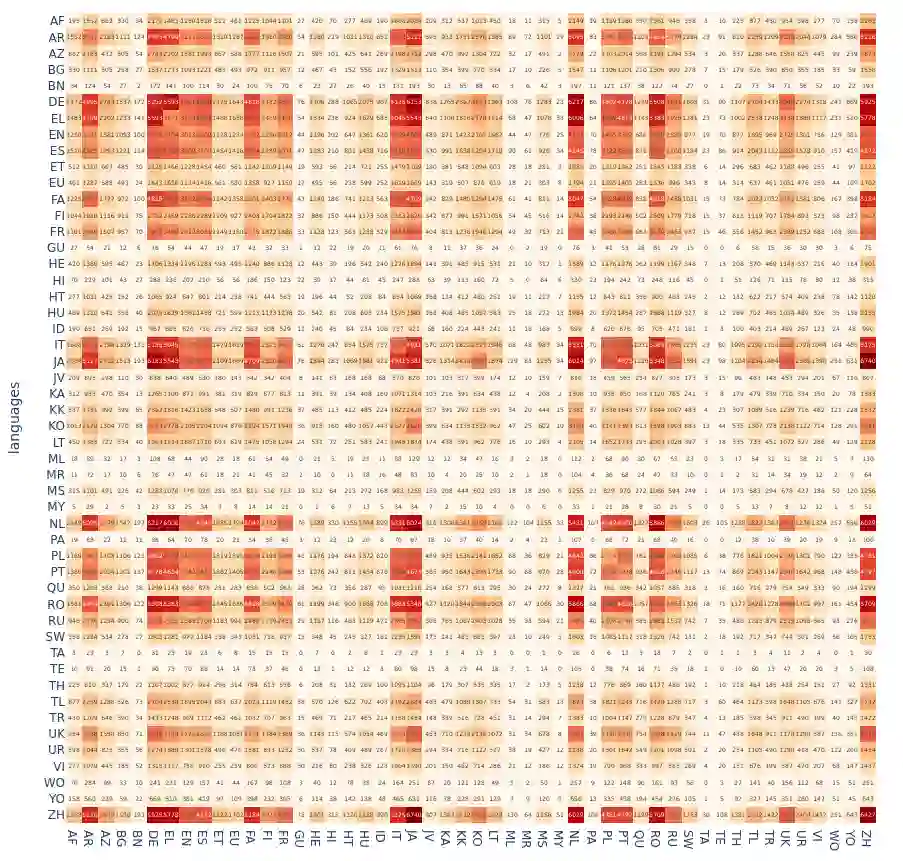
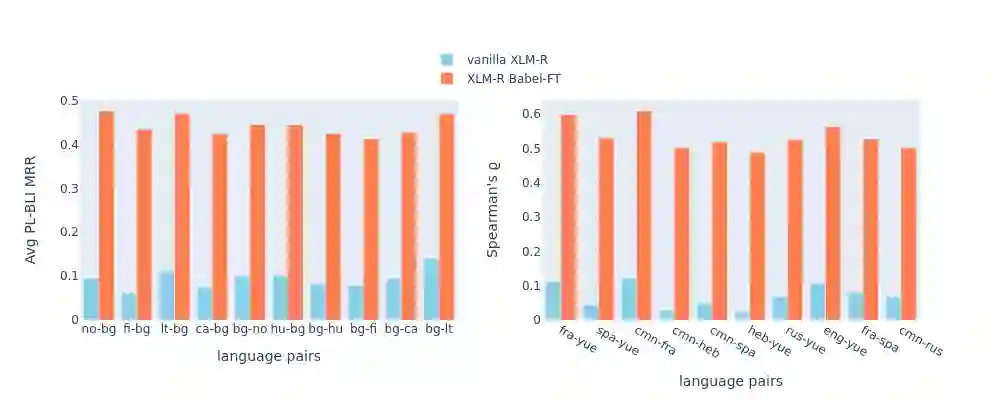
While pretrained language models (PLMs) primarily serve as general purpose text encoders that can be fine-tuned for a wide variety of downstream tasks, recent work has shown that they can also be rewired to produce high-quality word representations (i.e., static word embeddings) and yield good performance in type-level lexical tasks. While existing work primarily focused on lexical specialization of PLMs in monolingual and bilingual settings, in this work we expose massively multilingual transformers (MMTs, e.g., mBERT or XLM-R) to multilingual lexical knowledge at scale, leveraging BabelNet as the readily available rich source of multilingual and cross-lingual type-level lexical knowledge. Concretely, we leverage BabelNet's multilingual synsets to create synonym pairs across $50$ languages and then subject the MMTs (mBERT and XLM-R) to a lexical specialization procedure guided by a contrastive objective. We show that such massively multilingual lexical specialization brings massive gains in two standard cross-lingual lexical tasks, bilingual lexicon induction and cross-lingual word similarity, as well as in cross-lingual sentence retrieval. Crucially, we observe gains for languages unseen in specialization, indicating that the multilingual lexical specialization enables generalization to languages with no lexical constraints. In a series of subsequent controlled experiments, we demonstrate that the pretraining quality of word representations in the MMT for languages involved in specialization has a much larger effect on performance than the linguistic diversity of the set of constraints. Encouragingly, this suggests that lexical tasks involving low-resource languages benefit the most from lexical knowledge of resource-rich languages, generally much more available.
翻译:虽然事先培训的语言模型(PLMs)主要用作一般目的的文字解码器,可以微调用于各种各样的下游任务,但最近的工作表明,它们也可以重新连成高质量的文字表达(即静态的字嵌入)和在类型级词汇任务中产生良好的性能。虽然现有工作主要侧重于单语和双语环境中的PLMs词汇专业化,但在这项工作中,我们使大量多语种变异器(MMMTs,例如mBERT或XLM-R)在规模上获得多语种词汇学知识,利用BabelNet作为多种语言和跨语言类型字型词汇知识的现成的丰富专业化来源。 具体而言,我们利用BabelNet的多语种合成合成合成组合来创建50美元语言的同义配对,然后将MMMTs(mBERT和XLM-R-R)置于一个以对比目标为指导的词汇化程序。 在两种标准的跨语种语言任务中,使用双语的跨语言引入和跨语种语言解释的计算,我们从在通用语言的词汇学上显示一个类似语言的连进化的超语言进化,在通用语言学上,从我们定义中显示我们从多语言的跨语言的跨语言的连化学进进化学进进化学学学学学学学学学学的学的后,从我们在一般的学上显示了一种语言的跨学进进到在一般的学。