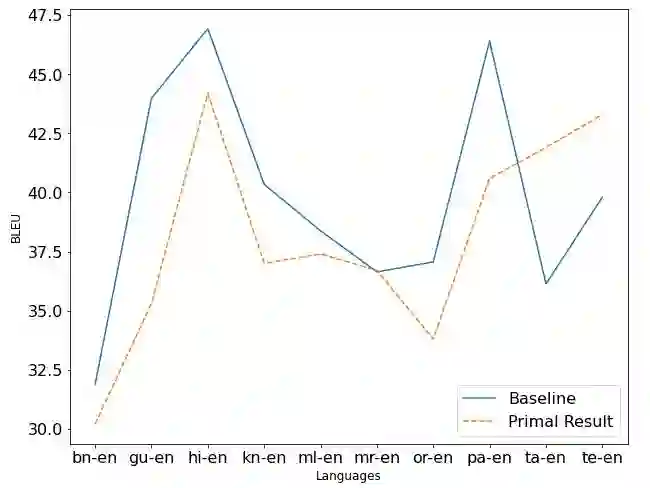
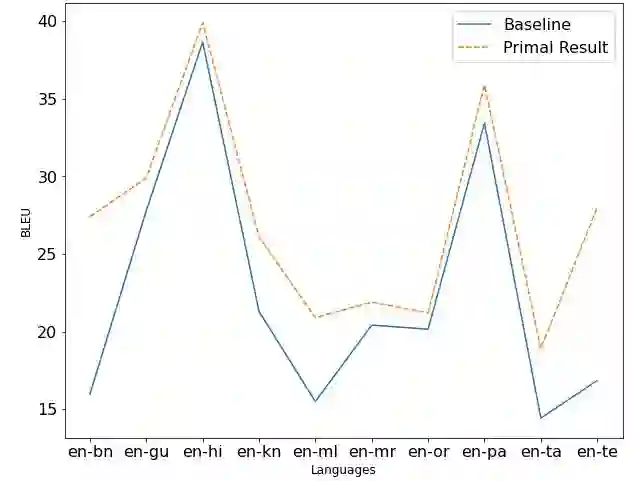
Machine Translation System (MTS) serves as an effective tool for communication by translating text or speech from one language to another language. The need of an efficient translation system becomes obvious in a large multilingual environment like India, where English and a set of Indian Languages (ILs) are officially used. In contrast with English, ILs are still entreated as low-resource languages due to unavailability of corpora. In order to address such asymmetric nature, multilingual neural machine translation (MNMT) system evolves as an ideal approach in this direction. In this paper, we propose a MNMT system to address the issues related to low-resource language translation. Our model comprises of two MNMT systems i.e. for English-Indic (one-to-many) and the other for Indic-English (many-to-one) with a shared encoder-decoder containing 15 language pairs (30 translation directions). Since most of IL pairs have scanty amount of parallel corpora, not sufficient for training any machine translation model. We explore various augmentation strategies to improve overall translation quality through the proposed model. A state-of-the-art transformer architecture is used to realize the proposed model. Trials over a good amount of data reveal its superiority over the conventional models. In addition, the paper addresses the use of language relationships (in terms of dialect, script, etc.), particularly about the role of high-resource languages of the same family in boosting the performance of low-resource languages. Moreover, the experimental results also show the advantage of backtranslation and domain adaptation for ILs to enhance the translation quality of both source and target languages. Using all these key approaches, our proposed model emerges to be more efficient than the baseline model in terms of evaluation metrics i.e BLEU (BiLingual Evaluation Understudy) score for a set of ILs.
翻译:机器翻译系统(MTS)是一个有效的沟通工具,将文本或语言从一种语言翻译到另一种语言。在印度这样的大型多语言环境中,高效翻译系统的需求变得显而易见,因为印度正式使用英语和一套印度语言(ILs),与英语相比,ILs仍然被作为低资源语言处理,因为没有Corbora。为了解决这种不对称性质,多语种神经机器翻译系统(MNMT)是朝着这个方向发展的一个理想的方法。在本文中,我们建议建立一个MNMT系统,以解决与低资源语言翻译有关的问题。我们的模式包括两个MNMT系统,即英语-Indica语(一对一)和印度语(一对一)两种语言。与英语(多语种)相比,IL(30个翻译方向)仍然被作为低资源解码语言处理。由于大多数IL对配对系统都缺乏平行的样本数量,不足以培训任何机器翻译模式。我们探索各种增强战略,以便通过提议的模型改进整体翻译质量。我们的两个MNMTMT(一至高语言版本)的关键语言翻译系统,在Servialalalal-lievalal lade real lade real real real real real lader lade lade lade lade lacuvalde laveal lade lauts lauts lauts lade lade lade lauts lax lauts lauts lade lade lade lade lade lade lauts a lauts lautes lauts lauts lauts lauts lauts lauts lautsal lauts lauts lauts lauts lauts lauts lauts lautsal lauts lauts lauts lauts a lauts lauts lauts lauts a la laut lauts a lauts lauts a lauts a lauts a la la lauts a la la la la