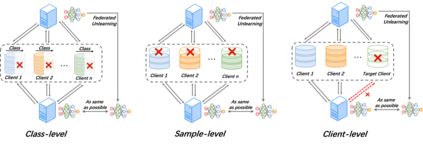
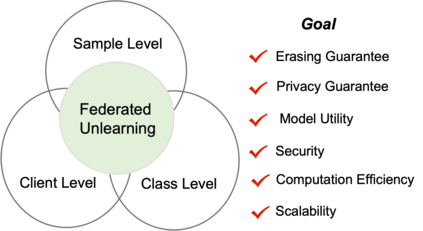
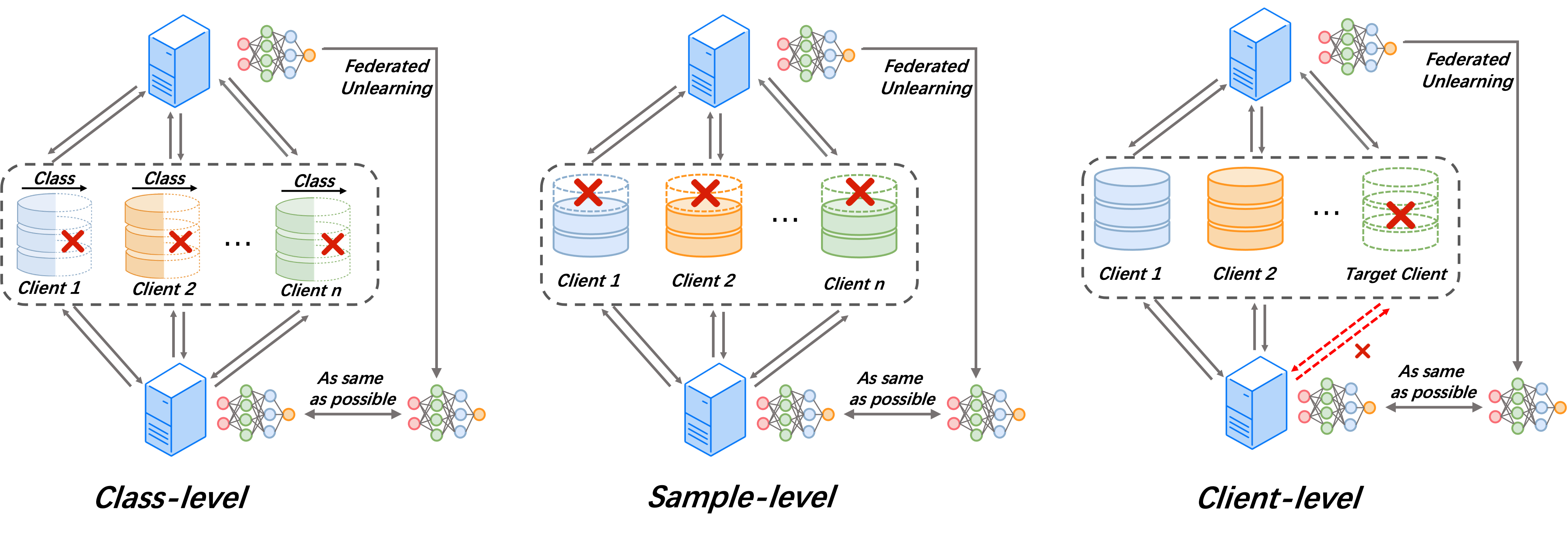
With the development of trustworthy Federated Learning (FL), the requirement of implementing right to be forgotten gives rise to the area of Federated Unlearning (FU). Comparing to machine unlearning, a major challenge of FU lies in the decentralized and privacy-preserving nature of FL, in which clients jointly train a global model without sharing their raw data, making it substantially more intricate to selectively unlearn specific information. In that regard, many efforts have been made to tackle the challenges of FU and have achieved significant progress. In this paper, we present a comprehensive survey of FU. Specially, we provide the existing algorithms, objectives, evaluation metrics, and identify some challenges of FU. By reviewing and comparing some studies, we summarize them into a taxonomy for various schemes, potential applications and future directions.
翻译:暂无翻译