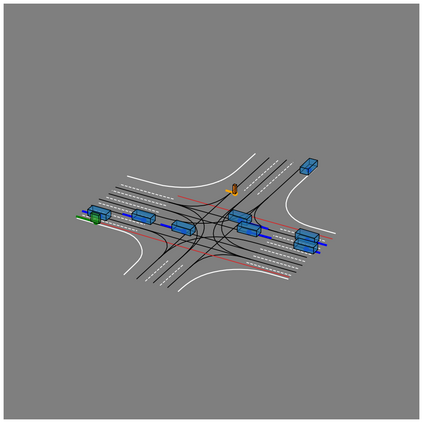
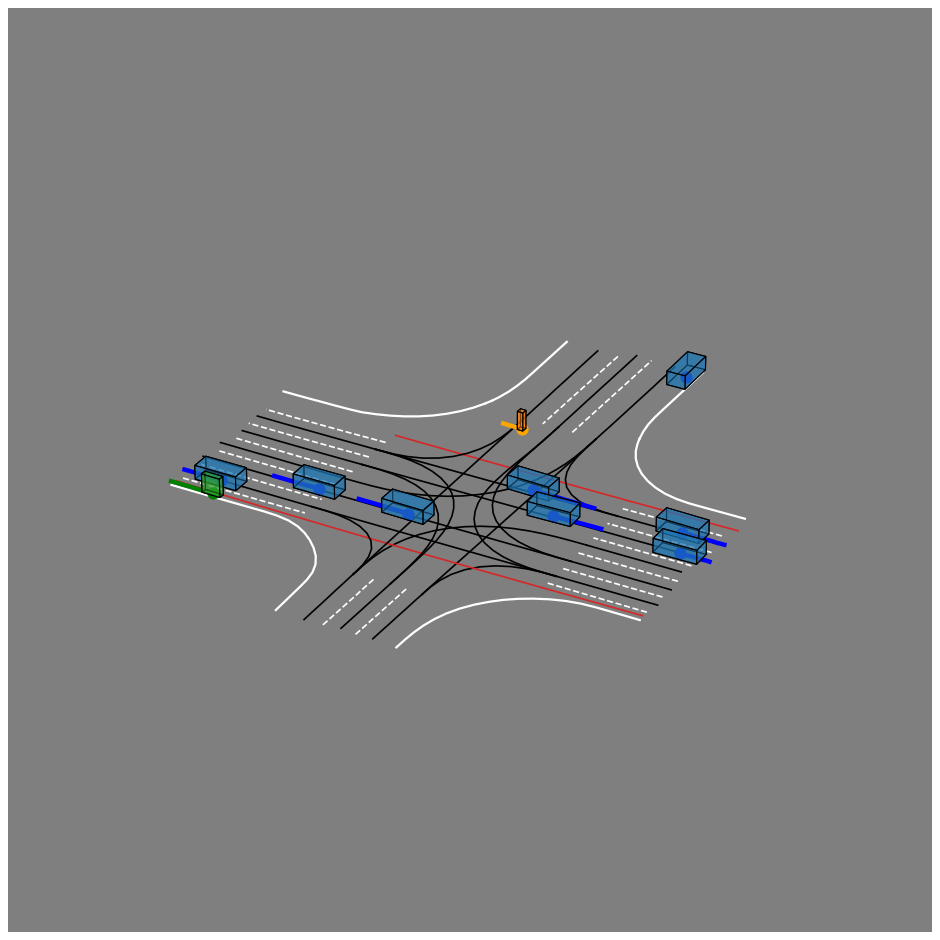
We present JointMotion, a self-supervised learning method for joint motion prediction in autonomous driving. Our method includes a scene-level objective connecting motion and environments, and an instance-level objective to refine learned representations. Our evaluations show that these objectives are complementary and outperform recent contrastive and autoencoding methods as pre-training for joint motion prediction. Furthermore, JointMotion adapts to all common types of environment representations used for motion prediction (i.e., agent-centric, scene-centric, and pairwise relative), and enables effective transfer learning between the Waymo Open Motion and the Argoverse 2 Forecasting datasets. Notably, our method improves the joint final displacement error of Wayformer, Scene Transformer, and HPTR by 3%, 7%, and 11%, respectively.
翻译:暂无翻译