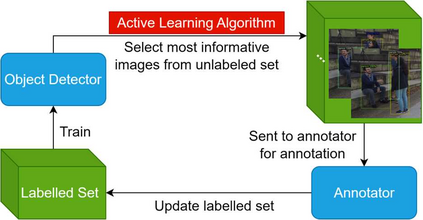
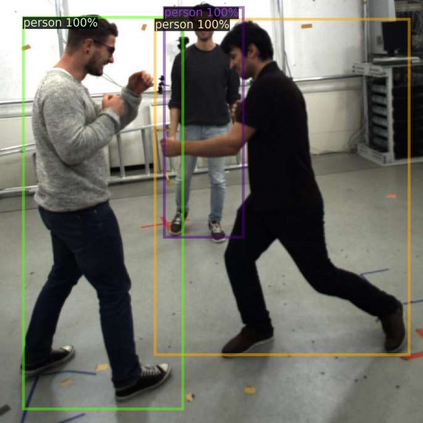
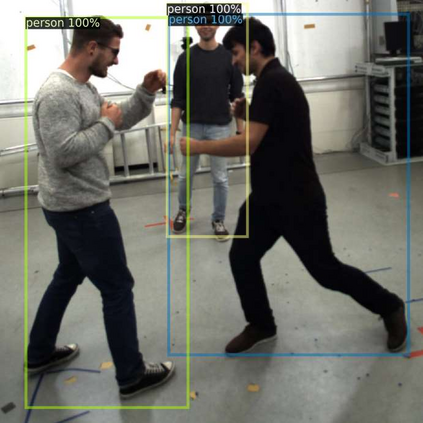
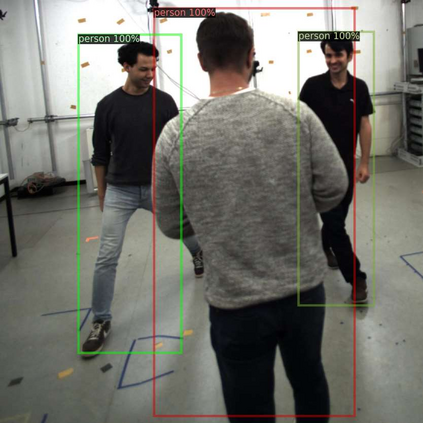
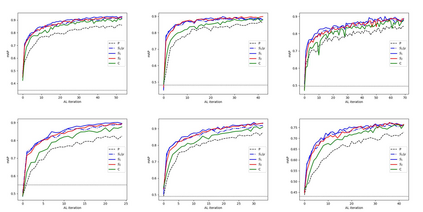
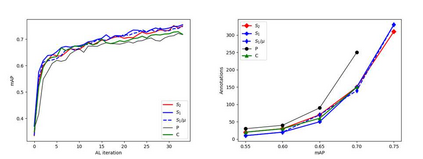
Object detection is one of the most important and fundamental aspects of computer vision tasks, which has been broadly utilized in pose estimation, object tracking and instance segmentation models. To obtain training data for object detection model efficiently, many datasets opt to obtain their unannotated data in video format and the annotator needs to draw a bounding box around each object in the images. Annotating every frame from a video is costly and inefficient since many frames contain very similar information for the model to learn from. How to select the most informative frames from a video to annotate has become a highly practical task to solve but attracted little attention in research. In this paper, we proposed a novel active learning algorithm for object detection models to tackle this problem. In the proposed active learning algorithm, both classification and localization informativeness of unlabelled data are measured and aggregated. Utilizing the temporal information from video frames, two novel localization informativeness measurements are proposed. Furthermore, a weight curve is proposed to avoid querying adjacent frames. Proposed active learning algorithm with multiple configurations was evaluated on the MuPoTS dataset and FootballPD dataset.
翻译:目标检测是计算机视觉任务中最重要、最基本的方面之一,被广泛应用于姿态估计、物体跟踪和实例分割模型中。为了有效地获取用于目标检测模型的训练数据,许多数据集选择以视频格式获取未注释的数据,并且注释者需要在图像中的每个对象周围绘制一个边界框。由于许多帧包含非常相似的信息供模型学习,从视频中注释每个帧的成本高昂且效率低下。选择从视频中注释最具信息量的帧已成为高度实用的任务,但在研究中很少引起关注。在本文中,我们提出了一种用于目标检测模型的新型主动学习算法来解决这个问题。在所提出的主动学习算法中,未标记数据的分类和定位信息均被测量和聚合。利用视频帧的时间信息,提出了两种新的定位信息测量方法。此外,还提出了一种权重曲线,以避免查询相邻的帧。在MuPoTS数据集和足球赛PD数据集上评估了具有多种配置的提议主动学习算法。