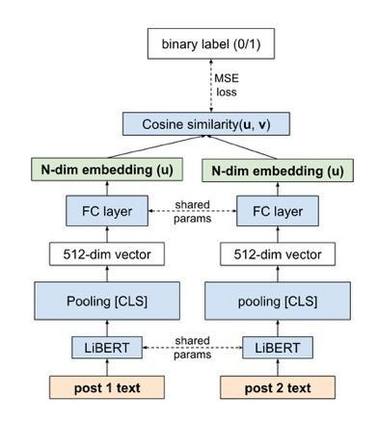
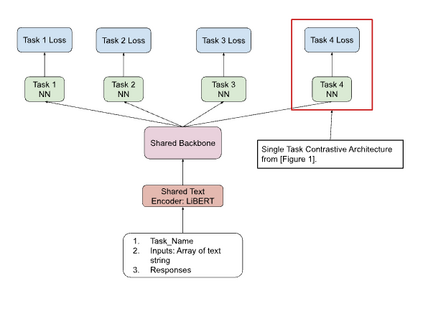
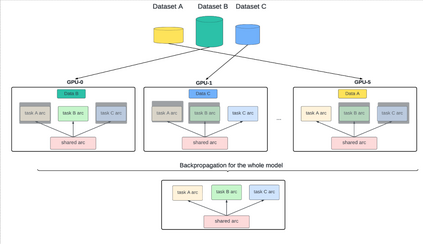
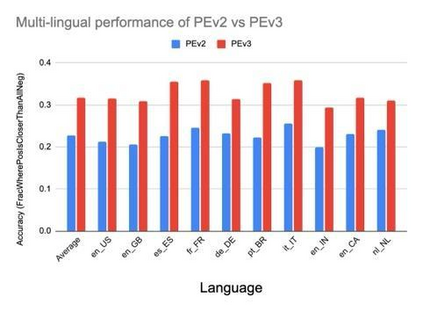
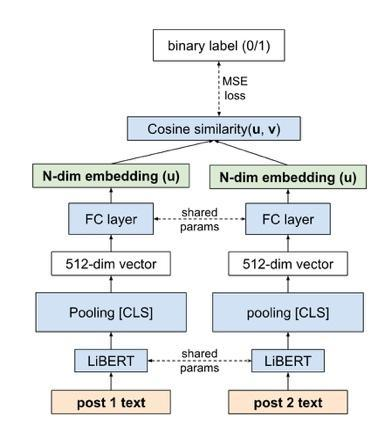
In enhancing LinkedIn core content recommendation models, a significant challenge lies in improving their semantic understanding capabilities. This paper addresses the problem by leveraging multi-task learning, a method that has shown promise in various domains. We fine-tune a pre-trained, transformer-based LLM using multi-task contrastive learning with data from a diverse set of semantic labeling tasks. We observe positive transfer, leading to superior performance across all tasks when compared to training independently on each. Our model outperforms the baseline on zero shot learning and offers improved multilingual support, highlighting its potential for broader application. The specialized content embeddings produced by our model outperform generalized embeddings offered by OpenAI on Linkedin dataset and tasks. This work provides a robust foundation for vertical teams across LinkedIn to customize and fine-tune the LLM to their specific applications. Our work offers insights and best practices for the field to build on.
翻译:暂无翻译