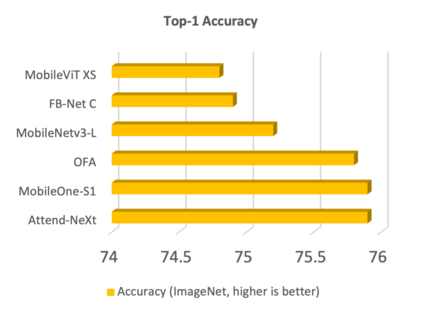
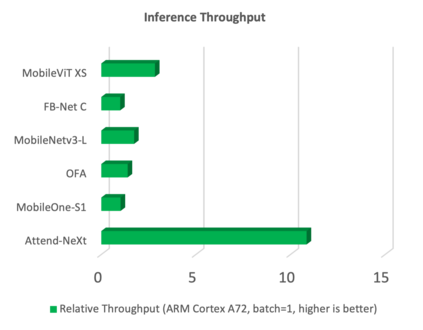
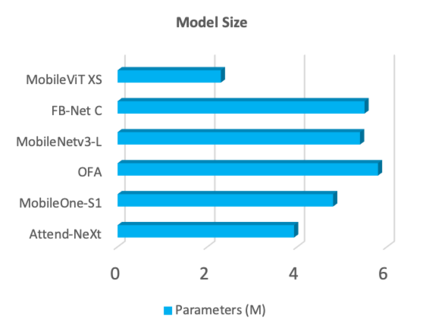
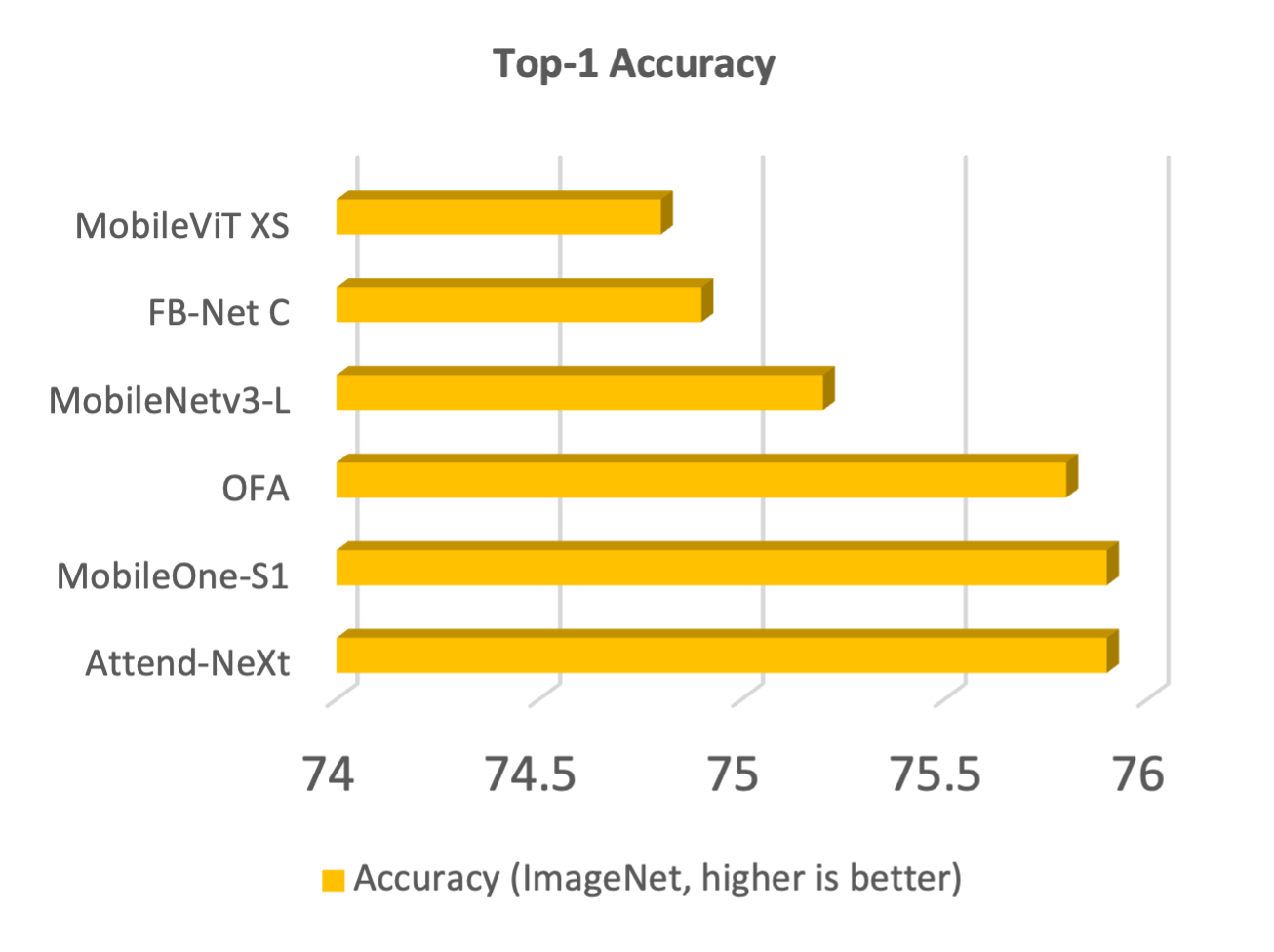
With the growing adoption of deep learning for on-device TinyML applications, there has been an ever-increasing demand for efficient neural network backbones optimized for the edge. Recently, the introduction of attention condenser networks have resulted in low-footprint, highly-efficient, self-attention neural networks that strike a strong balance between accuracy and speed. In this study, we introduce a faster attention condenser design called double-condensing attention condensers that allow for highly condensed feature embeddings. We further employ a machine-driven design exploration strategy that imposes design constraints based on best practices for greater efficiency and robustness to produce the macro-micro architecture constructs of the backbone. The resulting backbone (which we name AttendNeXt) achieves significantly higher inference throughput on an embedded ARM processor when compared to several other state-of-the-art efficient backbones (>10x faster than FB-Net C at higher accuracy and speed and >10x faster than MobileOne-S1 at smaller size) while having a small model size (>1.37x smaller than MobileNetv3-L at higher accuracy and speed) and strong accuracy (1.1% higher top-1 accuracy than MobileViT XS on ImageNet at higher speed). These promising results demonstrate that exploring different efficient architecture designs and self-attention mechanisms can lead to interesting new building blocks for TinyML applications.
翻译:随着人们越来越多地采用深入的学习方法来进行在设备上安装的微粒ML应用,对优化边缘优化的高效神经网络主干网的需求不断增加。最近,引入关注冷凝器网络导致低脚印、高效率和自控神经网络,从而在准确性和速度之间达到强烈的平衡。在这项研究中,我们引入了一种更快的注意冷凝器设计,称为双凝聚式冷凝器,允许高凝固特性嵌入。我们进一步采用了机械驱动的设计探索战略,根据提高效率和稳健性以形成骨干宏观-微型结构构建的最佳做法,在设计上设置了限制。由此形成的骨干(我们命名为NeXt)在嵌入的ARM进程上实现了显著的更低脚印、高效率的神经网络网络网络网络网络。 与其他最先进的节能骨架相比,我们引入了一个更快的注意冷凝压缩器设计,其精度和速度比Mmovey1-S1型设计速度快10x要快。我们还采用了一种机器驱动的设计探索型设计,其型规模小(比移动Net3-L结构更小,比移动网络结构更小,以更高,以更高的精度更高精度更高精度,以高的S-L,以高速度展示速度展示速度,在高级的S-V1-1号的S-V1号最高的图像结构,以高速度展示了速度,以高速度,在高级的自我结构结构显示,以更高的速度展示速度展示,在高。