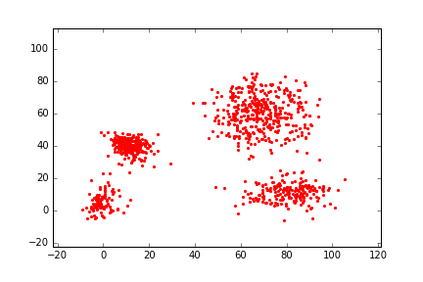
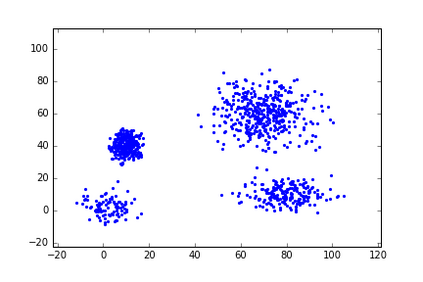
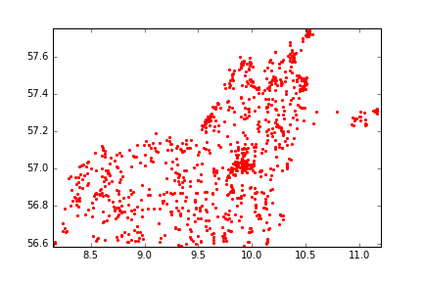
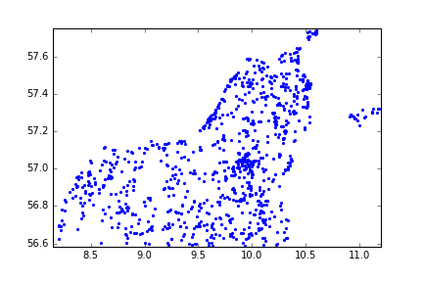
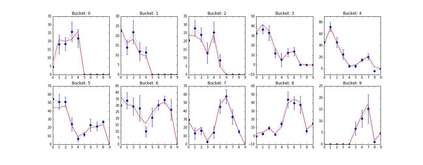
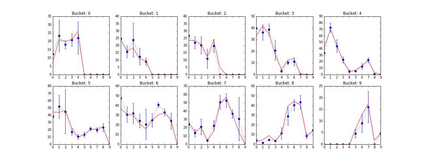
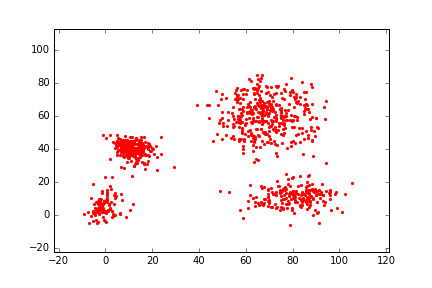
The Group-By query is an important kind of query, which is common and widely used in data warehouses, data analytics, and data visualization. Approximate query processing is an effective way to increase the querying efficiency on big data. The answer to a group-by query involves multiple values, which makes it difficult to provide sufficiently accurate estimations for all the groups. Stratified sampling improves the accuracy compared with the uniform sampling, but the samples chosen for some special queries cannot work for other queries. Online sampling chooses samples for the given query at query time, but it requires a long latency. Thus, it is a challenge to achieve both accuracy and efficiency at the same time. Facing such challenge, in this work, we propose a sample generation framework based on a conditional generative model. The sample generation framework can generate any number of samples for the given query without accessing the data. The proposed framework based on the lightweight model can be combined with stratified sampling and online aggregation to improve the estimation accuracy for group-by queries. The experimental results show that our proposed methods are both efficient and accurate.
翻译:组别查询是一种重要的查询类型,在数据仓库、数据分析和数据可视化中广泛使用,这是常见的。近似查询处理是提高大数据查询效率的有效方法。对组别查询的答案涉及多个数值,因此难以为所有组别提供足够准确的估计。分层抽样比统一抽样更能提高准确性,但为某些特殊查询选择的样本不能用于其他查询。在线抽样在查询时间选择给定查询的样本,但需要较长的延缓度。因此,实现准确性和效率是一项挑战。在这项工作中,面对这种挑战,我们提议以有条件的基因化模型为基础建立抽样生成框架。抽样生成框架可以在不访问数据的情况下为给定查询生成任何数量的样本。基于轻量模型的拟议框架可以与分层抽样和在线汇总相结合,以提高小组查询的估计准确性。实验结果显示,我们所提议的方法既有效又准确。