
题目: Natural Language Processing and Query Expansion
简介:
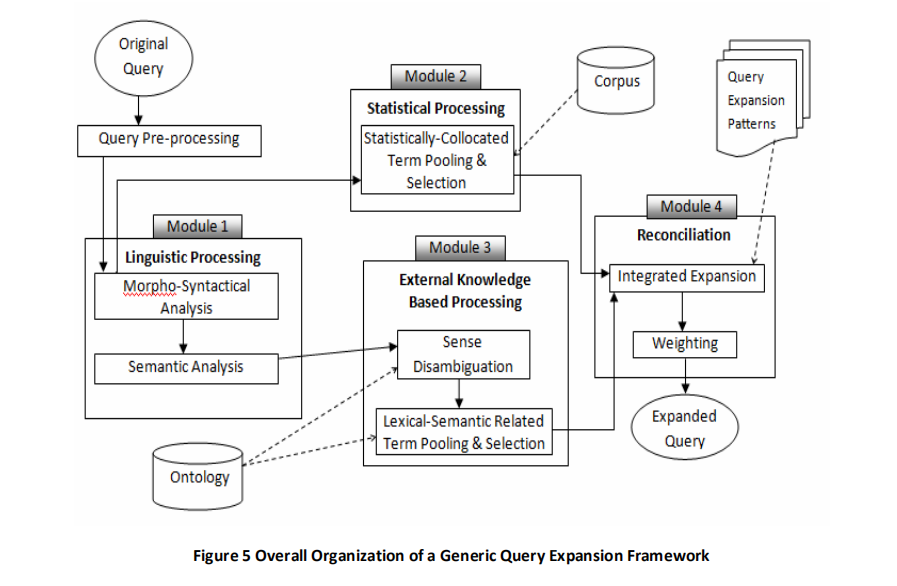
大量知识资源的可用性刺激了开发和增强信息检索技术的大量工作。用户的信息需求以自然语言表达,成功的检索很大程度上取决于预期目的的有效沟通。自然语言查询包含多种语言功能,这些语言功能代表了预期的搜索目标。导致语义歧义和对查询的误解以及其他因素(例如,对搜索环境缺乏了解)的语言特征会影响用户准确表示其信息需求的能力,这是由概念意图差距造成的。后者直接影响返回的搜索结果的相关性,而这可能不会使用户满意,因此是影响信息检索系统有效性的主要问题。我们讨论的核心是通过手动或自动捕获有意义的术语,短语甚至潜在的表示形式来识别表征查询意图及其丰富特征的重要组成部分,以手动或自动捕获它们的预期含义。具体而言,我们讨论了实现丰富化的技术,尤其是那些利用从文档语料库中的术语相关性的统计处理或从诸如本体之类的外部知识源中收集的信息的技术。我们提出了基于通用语言的查询扩展框架的结构,并提出了基于模块的分解,涵盖了来自查询处理,信息检索,计算语言学和本体工程的主题问题。对于每个模块,我们都会根据所使用的技术回顾分类和分析的文献中的最新解决方案。
成为VIP会员查看完整内容

相关内容

专知会员服务
140+阅读 · 2020年7月10日
专知会员服务
80+阅读 · 2020年3月5日
Arxiv
4+阅读 · 2017年8月17日

相关VIP内容
专知会员服务
140+阅读 · 2020年7月10日
专知会员服务
80+阅读 · 2020年3月5日
相关资讯
相关论文
Arxiv
4+阅读 · 2017年8月17日