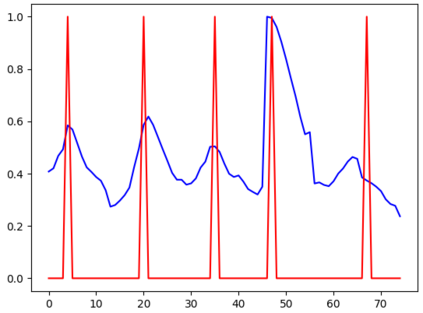
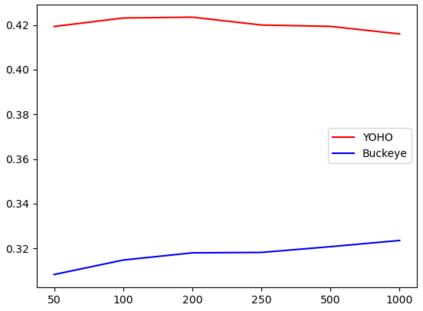
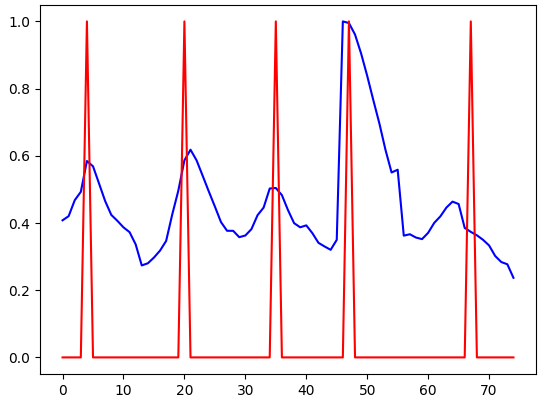
In this paper, we propose an unsupervised kNN-based approach for word segmentation in speech utterances. Our method relies on self-supervised pre-trained speech representations, and compares each audio segment of a given utterance to its K nearest neighbors within the training set. Our main assumption is that a segment containing more than one word would occur less often than a segment containing a single word. Our method does not require phoneme discovery and is able to operate directly on pre-trained audio representations. This is in contrast to current methods that use a two-stage approach; first detecting the phonemes in the utterance and then detecting word-boundaries according to statistics calculated on phoneme patterns. Experiments on two datasets demonstrate improved results over previous single-stage methods and competitive results on state-of-the-art two-stage methods.
翻译:在本文中,我们提出了一种不受监督的 kNN 语言语句分隔法。 我们的方法依赖于自我监督的事先培训的语音演示, 并在培训中将特定语句的每个音频段与 K 最近的邻里进行对比。 我们的主要假设是, 包含多个单词的段段会比包含单词的段段要少一些。 我们的方法不需要电话探索,并且能够直接在预先培训的音频演示中操作。 这与目前使用两阶段方法形成对照; 我们首先在语句中探测电话,然后根据按电话模式计算的统计数据探测单词边界。 对两个数据集的实验表明,与以往的单阶段方法相比,结果会有所改善,而且与最先进的两阶段方法的竞争性结果不同。