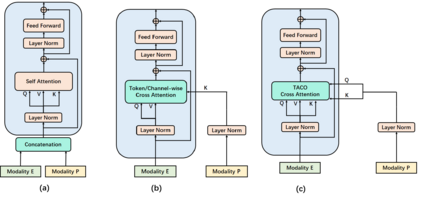
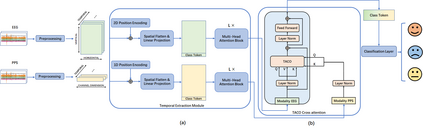
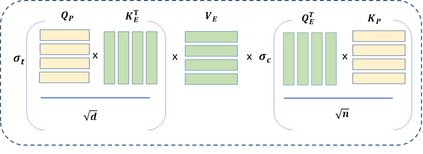
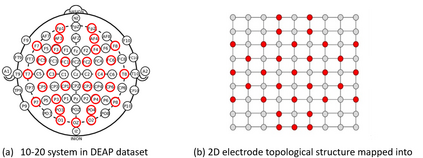
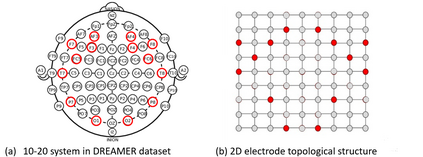
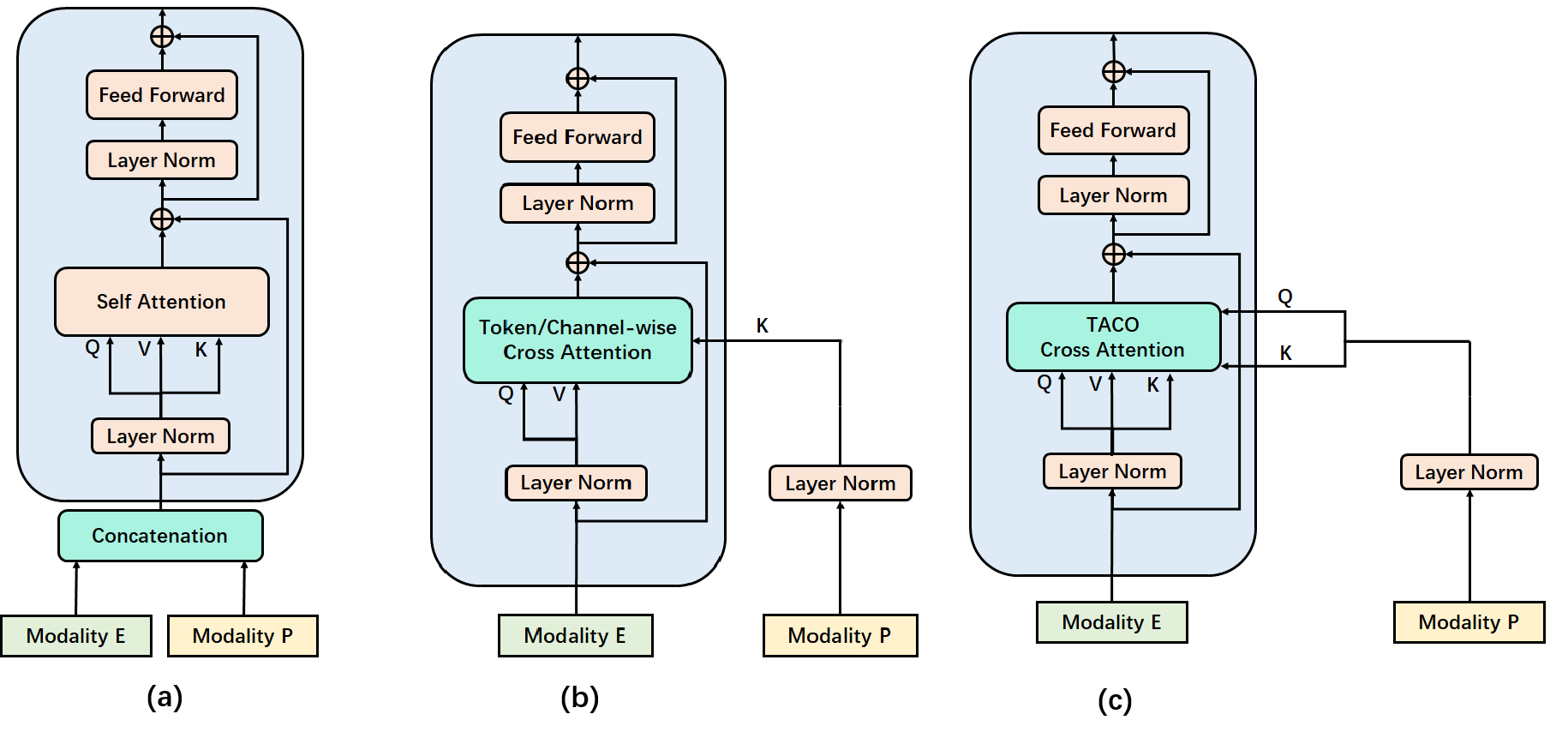
Recently, emotion recognition based on physiological signals has emerged as a field with intensive research. The utilization of multi-modal, multi-channel physiological signals has significantly improved the performance of emotion recognition systems, due to their complementarity. However, effectively integrating emotion-related semantic information from different modalities and capturing inter-modal dependencies remains a challenging issue. Many existing multimodal fusion methods ignore either token-to-token or channel-to-channel correlations of multichannel signals from different modalities, which limits the classification capability of the models to some extent. In this paper, we propose a comprehensive perspective of multimodal fusion that integrates channel-level and token-level cross-modal interactions. Specifically, we introduce a unified cross attention module called Token-chAnnel COmpound (TACO) Cross Attention to perform multimodal fusion, which simultaneously models channel-level and token-level dependencies between modalities. Additionally, we propose a 2D position encoding method to preserve information about the spatial distribution of EEG signal channels, then we use two transformer encoders ahead of the fusion module to capture long-term temporal dependencies from the EEG signal and the peripheral physiological signal, respectively. Subject-independent experiments on emotional dataset DEAP and Dreamer demonstrate that the proposed model achieves state-of-the-art performance.
翻译:暂无翻译