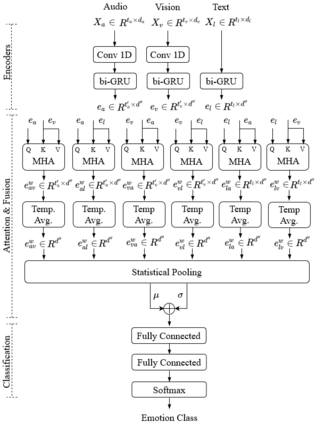
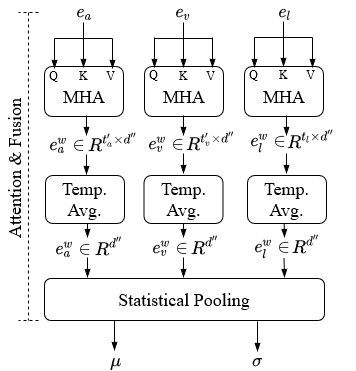
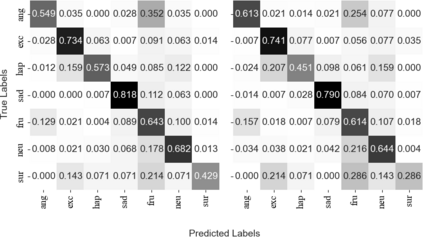
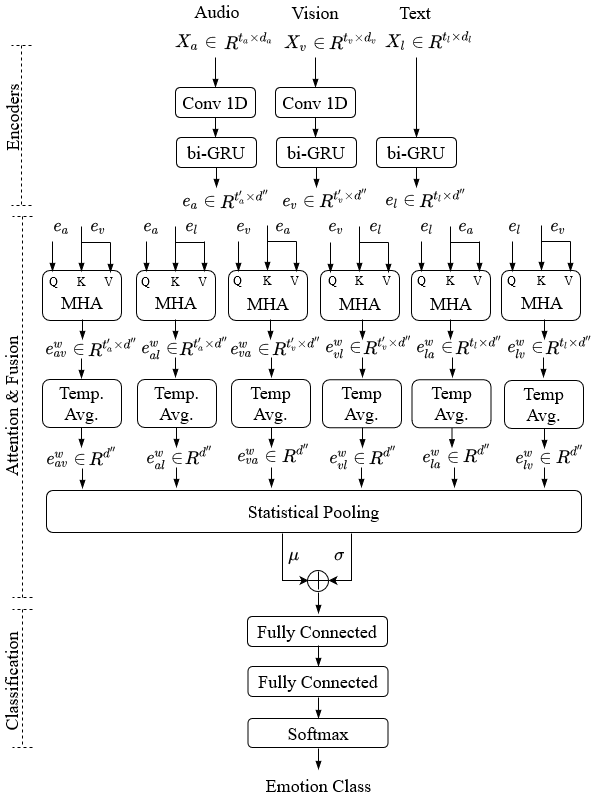
Humans express their emotions via facial expressions, voice intonation and word choices. To infer the nature of the underlying emotion, recognition models may use a single modality, such as vision, audio, and text, or a combination of modalities. Generally, models that fuse complementary information from multiple modalities outperform their uni-modal counterparts. However, a successful model that fuses modalities requires components that can effectively aggregate task-relevant information from each modality. As cross-modal attention is seen as an effective mechanism for multi-modal fusion, in this paper we quantify the gain that such a mechanism brings compared to the corresponding self-attention mechanism. To this end, we implement and compare a cross-attention and a self-attention model. In addition to attention, each model uses convolutional layers for local feature extraction and recurrent layers for global sequential modelling. We compare the models using different modality combinations for a 7-class emotion classification task using the IEMOCAP dataset. Experimental results indicate that albeit both models improve upon the state-of-the-art in terms of weighted and unweighted accuracy for tri- and bi-modal configurations, their performance is generally statistically comparable. The code to replicate the experiments is available at https://github.com/smartcameras/SelfCrossAttn
翻译:人类通过面部表情、声音和单词选择表达情感; 为推断基本情感的性质, 识别模型可能使用单一模式, 如视觉、 音频和文字, 或多种模式的组合。 一般来说, 将多种模式的补充信息结合在一起的模型优于单一模式。 然而, 组合模式的成功模型需要能够有效地汇总与任务有关的信息的组件。 跨模式关注被视为多模式融合的有效机制, 本文中我们量化了这种机制与相应的自我注意机制相比带来的收益。 为此, 我们实施并比较了一个交叉注意和自我注意模式。 除了注意外, 每种模型使用进化层来提取本地特征, 以及全球连续建模的反复层。 我们用IMOCCAP数据集比较了7级情感分类任务的不同模式组合。 实验结果显示, 尽管这两种模型在加权和非加权精确的三审和双摩模式精确度方面都取得了进步。 其业绩一般是可比较的, 在三审和双摩模式/ 自定义的模型上, 可以进行可比较。