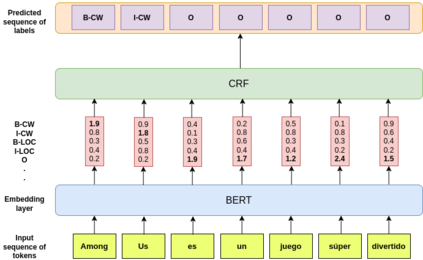
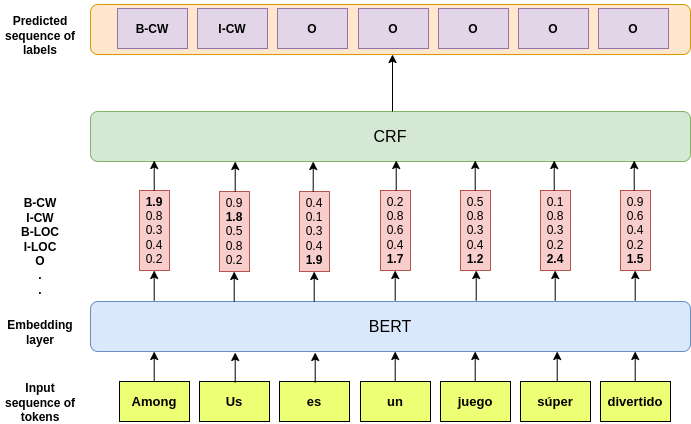
We leverage pre-trained language models to solve the task of complex NER for two low-resource languages: Chinese and Spanish. We use the technique of Whole Word Masking(WWM) to boost the performance of masked language modeling objective on large and unsupervised corpora. We experiment with multiple neural network architectures, incorporating CRF, BiLSTMs, and Linear Classifiers on top of a fine-tuned BERT layer. All our models outperform the baseline by a significant margin and our best performing model obtains a competitive position on the evaluation leaderboard for the blind test set.
翻译:我们利用预先培训的语言模型来解决两种低资源语言(中文和西班牙文)的复杂净入学率任务。我们使用全词遮掩技术(WWM)来提高大型和不受监督公司蒙面语言建模目标的性能。我们试验多种神经网络结构,在经过微调的BERT层之上纳入通用报告格式、BLSTMs和线性分类器。我们的所有模型都大大超过基线,我们最优秀的模型在盲人测试组的评价领导板上获得了竞争地位。