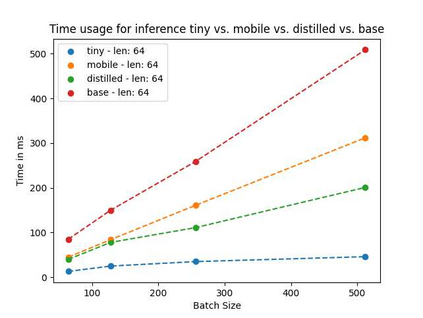
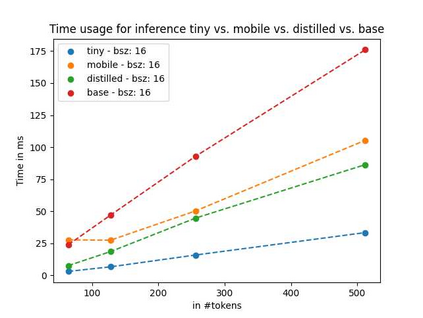
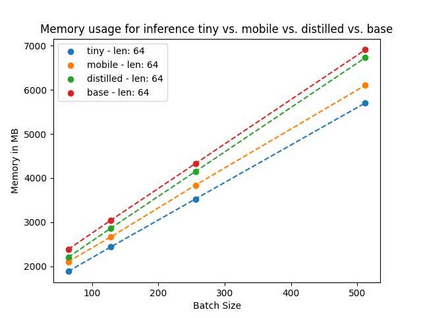
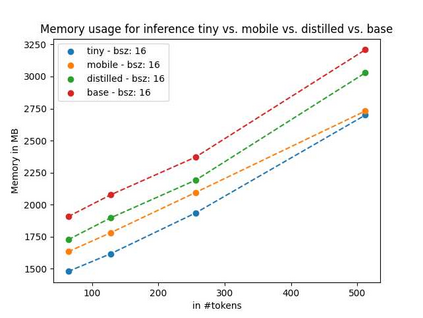
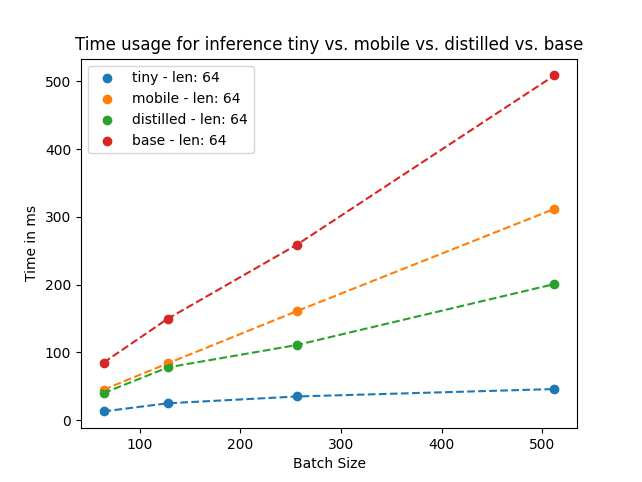
Language models pre-trained on biomedical corpora, such as BioBERT, have recently shown promising results on downstream biomedical tasks. Many existing pre-trained models, on the other hand, are resource-intensive and computationally heavy owing to factors such as embedding size, hidden dimension, and number of layers. The natural language processing (NLP) community has developed numerous strategies to compress these models utilising techniques such as pruning, quantisation, and knowledge distillation, resulting in models that are considerably faster, smaller, and subsequently easier to use in practice. By the same token, in this paper we introduce six lightweight models, namely, BioDistilBERT, BioTinyBERT, BioMobileBERT, DistilBioBERT, TinyBioBERT, and CompactBioBERT which are obtained either by knowledge distillation from a biomedical teacher or continual learning on the Pubmed dataset via the Masked Language Modelling (MLM) objective. We evaluate all of our models on three biomedical tasks and compare them with BioBERT-v1.1 to create efficient lightweight models that perform on par with their larger counterparts. All the models will be publicly available on our Huggingface profile at https://huggingface.co/nlpie and the codes used to run the experiments will be available at https://github.com/nlpie-research/Compact-Biomedical-Transformers.
翻译:在生物医学公司(如BioBERT)上预先培训过的语文模型最近显示下游生物医学任务有可喜的成果。另一方面,由于嵌入体积、隐藏尺寸和层数等因素,许多现有的预先培训模式资源密集且计算繁重。自然语言处理(NLP)社区制定了许多战略,以压缩这些模型,这些模型利用诸如修剪、量化和知识蒸馏等技术,导致模型在下游生物医学任务上大大加快、缩小并随后更容易使用。同样,我们在本文件中引入了六种轻量模型,即:BioDistilBERT、BioBERT、BioMobileBERT、DitilBioBERT、TinyyBERT和ClaimBioBERT, 和ClaimBERT。这些模型要么是生物医学教师的知识蒸馏,要么是不断通过遮掩语言模型(MLMMM)的目标在普式数据集上学习。我们所有关于三项生物医学任务的透明模型,然后与BERT-VGUB-1-1-1-1-1和高效的轻质模型,然后在使用。