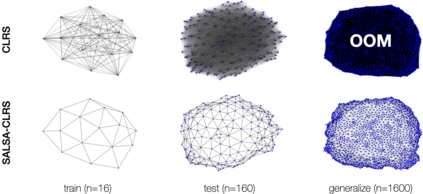
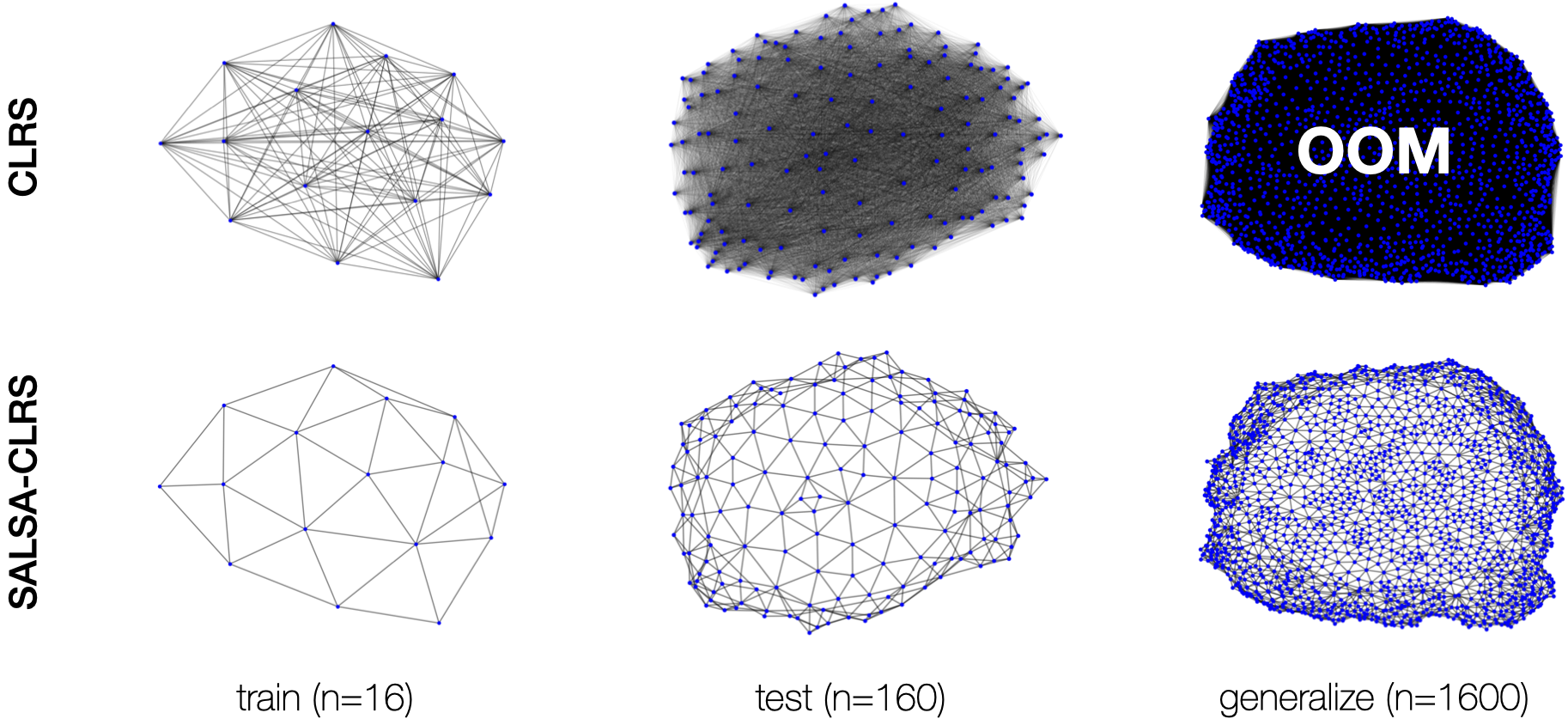
We introduce an extension to the CLRS algorithmic learning benchmark, prioritizing scalability and the utilization of sparse representations. Many algorithms in CLRS require global memory or information exchange, mirrored in its execution model, which constructs fully connected (not sparse) graphs based on the underlying problem. Despite CLRS's aim of assessing how effectively learned algorithms can generalize to larger instances, the existing execution model becomes a significant constraint due to its demanding memory requirements and runtime (hard to scale). However, many important algorithms do not demand a fully connected graph; these algorithms, primarily distributed in nature, align closely with the message-passing paradigm employed by Graph Neural Networks. Hence, we propose SALSA-CLRS, an extension of the current CLRS benchmark specifically with scalability and sparseness in mind. Our approach includes adapted algorithms from the original CLRS benchmark and introduces new problems from distributed and randomized algorithms. Moreover, we perform a thorough empirical evaluation of our benchmark. Code is publicly available at https://github.com/jkminder/SALSA-CLRS.
翻译:暂无翻译