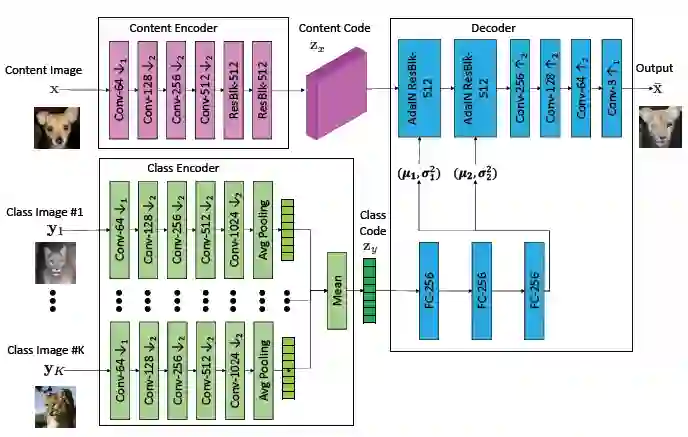
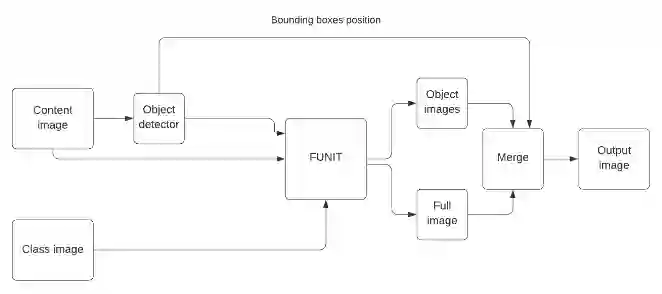
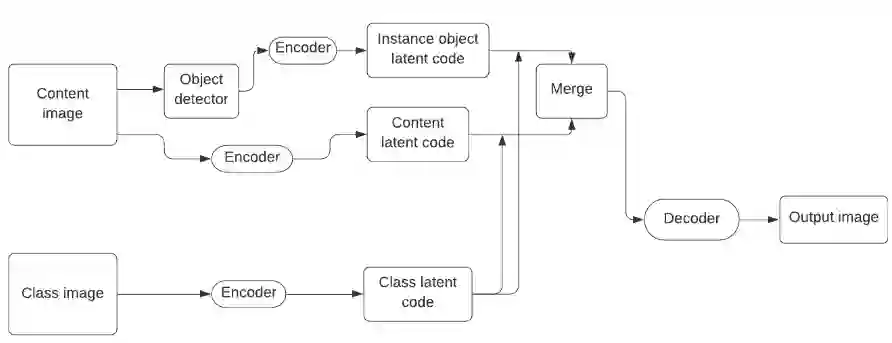
Unsupervised image-to-image translation methods have received a lot of attention in the last few years. Multiple techniques emerged tackling the initial challenge from different perspectives. Some focus on learning as much as possible from several target style images for translations while other make use of object detection in order to produce more realistic results on content-rich scenes. In this work, we assess how a method that has initially been developed for single object translation performs on more diverse and content-rich images. Our work is based on the FUNIT[1] framework and we train it with a more diverse dataset. This helps understanding how such method behaves beyond their initial frame of application. We present a way to extend a dataset based on object detection. Moreover, we propose a way to adapt the FUNIT framework in order to leverage the power of object detection that one can see in other methods.
翻译:在过去几年里,未经监督的图像到图像翻译方法受到了很多关注。从不同角度处理最初的挑战出现了多种技术。有些技术侧重于尽可能多地从一些目标风格的图像中学习翻译图像,而另一些则侧重于利用对象探测,以便在内容丰富的场景上产生更现实的结果。在这项工作中,我们评估了最初为单一对象翻译开发的方法如何以更加多样和内容丰富的图像进行演化。我们的工作以FUNIT框架为基础,我们用更多样化的数据集对它进行培训。这有助于了解这种方法在最初应用框架之外如何运作。我们提出了一个扩大基于对象探测的数据集的途径。此外,我们提出了调整FUNIT框架的方法,以便利用其他方法中可以看到的物体探测能力。