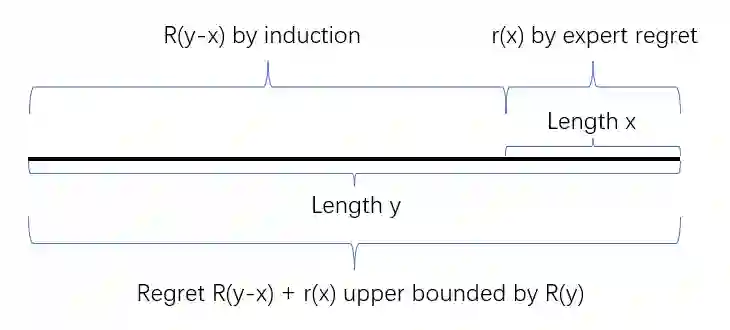
In online convex optimization, the player aims to minimize regret, or the difference between her loss and that of the best fixed decision in hindsight over the entire repeated game. Algorithms that minimize (standard) regret may converge to a fixed decision, which is undesirable in changing or dynamic environments. This motivates the stronger metrics of performance, notably adaptive and dynamic regret. Adaptive regret is the maximum regret over any continuous sub-interval in time. Dynamic regret is the difference between the total cost and that of the best sequence of decisions in hindsight. State-of-the-art performance in both adaptive and dynamic regret minimization suffers a computational penalty - typically on the order of a multiplicative factor that grows logarithmically in the number of game iterations. In this paper we show how to reduce this computational penalty to be doubly logarithmic in the number of game iterations, and retain near optimal adaptive and dynamic regret bounds.
翻译:在在线 convex 优化中, 玩家旨在最小化遗憾, 或最小化其损失与后视整个重复游戏中最佳固定决定的差错。 最小化( 标准) 遗憾的算法可能会趋同于固定的决定, 这对于变化或动态环境来说是不可取的。 这激励着更强的性能衡量标准, 特别是适应性和动态的后悔。 适应性遗憾是任何连续的次互动时间中的最大遗憾。 动态遗憾是事后观察中决定的总成本和最佳顺序的总成本之间的差。 适应性和动态最小化中最先进的成绩都会受到计算处罚, 通常是在游戏迭代数中增加对数的多复制因素顺序上。 本文我们展示如何减少这一计算性惩罚, 使游戏迭代数的对数加倍对数, 并保持接近最佳的适应性和动态后悔界限 。