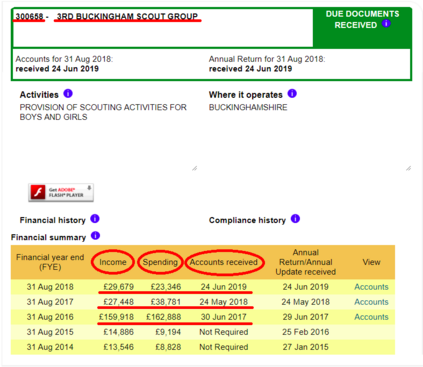
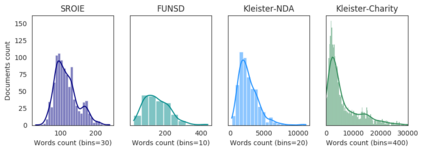
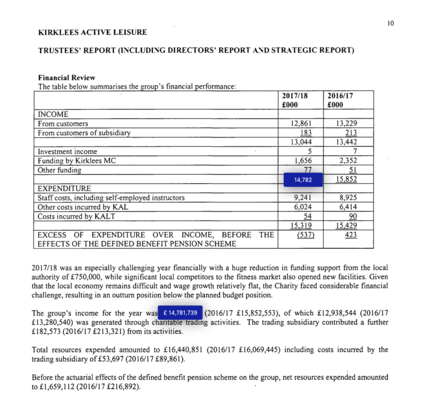
The relevance of the Key Information Extraction (KIE) task is increasingly important in natural language processing problems. But there are still only a few well-defined problems that serve as benchmarks for solutions in this area. To bridge this gap, we introduce two new datasets (Kleister NDA and Kleister Charity). They involve a mix of scanned and born-digital long formal English-language documents. In these datasets, an NLP system is expected to find or infer various types of entities by employing both textual and structural layout features. The Kleister Charity dataset consists of 2,788 annual financial reports of charity organizations, with 61,643 unique pages and 21,612 entities to extract. The Kleister NDA dataset has 540 Non-disclosure Agreements, with 3,229 unique pages and 2,160 entities to extract. We provide several state-of-the-art baseline systems from the KIE domain (Flair, BERT, RoBERTa, LayoutLM, LAMBERT), which show that our datasets pose a strong challenge to existing models. The best model achieved an 81.77% and an 83.57% F1-score on respectively the Kleister NDA and the Kleister Charity datasets. We share the datasets to encourage progress on more in-depth and complex information extraction tasks.
翻译:关键信息提取(KIE)任务的相关性在自然语言处理问题中越来越重要。但是,仍然只有几个明确界定的问题,成为这一领域解决办法的基准。为了弥合这一差距,我们引入了两个新的数据集(Kleister NDA和Kleister Charlister)。它们包含扫描和出生数字式长长的英文正式文件的组合。在这些数据集中,预计一个NLP系统将使用文字和结构布局功能,找到或推断各种类型的实体。Kleister慈善数据集由慈善组织的年度财务报告2 788份组成,其中61 643页是独一无二的,21 612个实体要提取。Kleister NDA数据集有540个非披露协议,其中3 229页是独特的,2 160个实体要提取。我们提供了来自KIEE域(Flair、BERT、RoBERT、DLM、LM、LMLEMERT)的一些最先进的基线系统,其中显示,我们的数据集对现有模型构成强烈的挑战。最佳模型在81.77%和83.57%的FIAISTO分别提供了我们的核心数据。