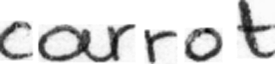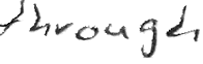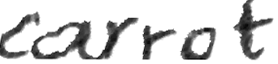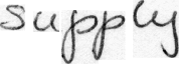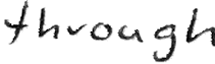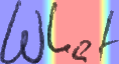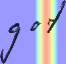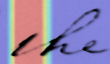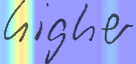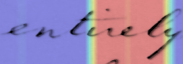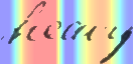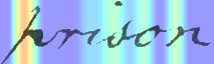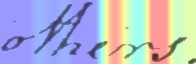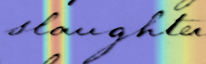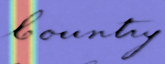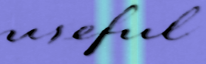Performances of Handwritten Text Recognition (HTR) models are largely determined by the availability of labeled and representative training samples. However, in many application scenarios labeled samples are scarce or costly to obtain. In this work, we propose a self-training approach to train a HTR model solely on synthetic samples and unlabeled data. The proposed training scheme uses an initial model trained on synthetic data to make predictions for the unlabeled target dataset. Starting from this initial model with rather poor performance, we show that a considerable adaptation is possible by training against the predicted pseudo-labels. Moreover, the investigated self-training strategy does not require any manually annotated training samples. We evaluate the proposed method on four widely used benchmark datasets and show its effectiveness on closing the gap to a model trained in a fully-supervised manner.
翻译:手写文本识别模型(HTR)的性能主要取决于是否有贴标签和具有代表性的培训样本,然而,在许多应用中,贴标签的样本很少,或获取成本很高;在这项工作中,我们提议采用自我培训办法,只对合成样品和无标签数据进行HTR模型培训;拟议培训计划使用经过合成数据培训的初始模型,对未贴标签的目标数据集作出预测;从这一初始模型开始,我们表现较差,我们表明通过针对预测的假标签进行培训,可以进行大量调整;此外,调查的自我培训战略不需要人工附加说明的培训样本;我们评估了四个广泛使用的基准数据集的拟议方法,并展示了该方法在缩小差距方面的效力,以完全监督的方式培训了模型。