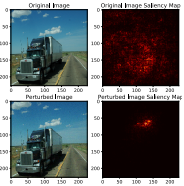
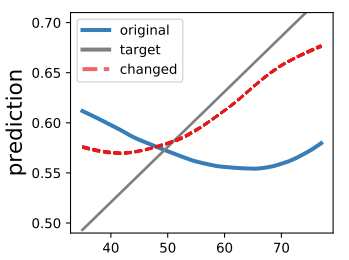
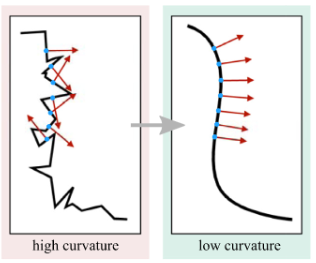
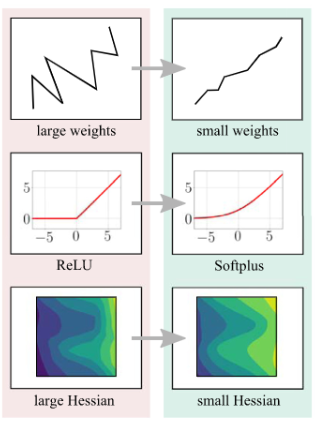
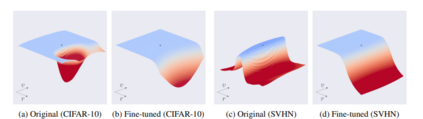
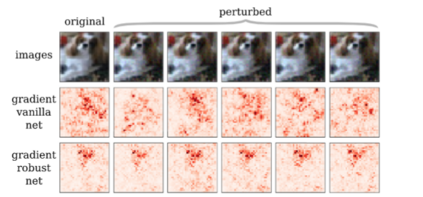
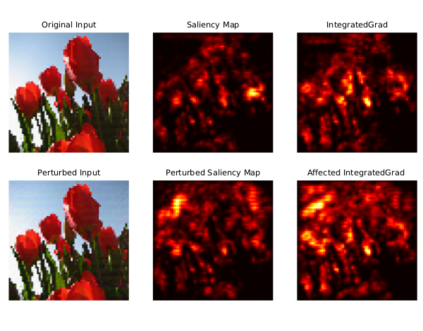
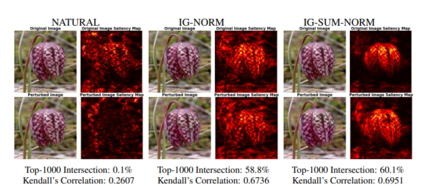
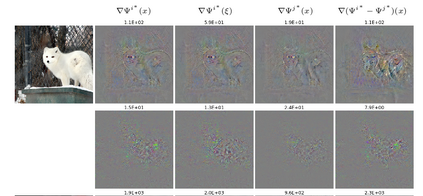
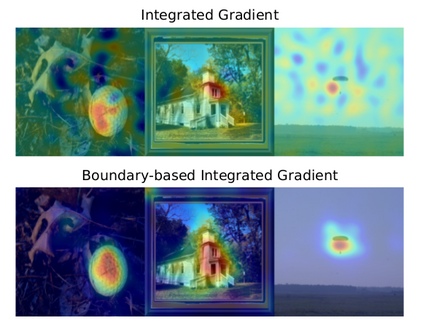
Explainability has been widely stated as a cornerstone of the responsible and trustworthy use of machine learning models. With the ubiquitous use of Deep Neural Network (DNN) models expanding to risk-sensitive and safety-critical domains, many methods have been proposed to explain the decisions of these models. Recent years have also seen concerted efforts that have shown how such explanations can be distorted (attacked) by minor input perturbations. While there have been many surveys that review explainability methods themselves, there has been no effort hitherto to assimilate the different methods and metrics proposed to study the robustness of explanations of DNN models. In this work, we present a comprehensive survey of methods that study, understand, attack, and defend explanations of DNN models. We also present a detailed review of different metrics used to evaluate explanation methods, as well as describe attributional attack and defense methods. We conclude with lessons and take-aways for the community towards ensuring robust explanations of DNN model predictions.
翻译:人们广泛认为,解释性是负责任和可信赖地使用机器学习模型的基石。随着深神经网络模型普遍被用于扩大至风险敏感和安全关键领域,提出了许多方法来解释这些模型的决定。近年来,人们还一致作出努力,表明这种解释如何被小的输入干扰扭曲(攻击)。虽然许多调查都审查了解释性方法本身,但迄今没有努力吸收为研究DNN模型的可靠解释而提出的不同方法和指标。我们在此工作中对研究、理解、攻击和维护DNN模型解释的方法进行了全面调查。我们还详细审查了用于评价解释方法的不同指标,并描述了归属攻击和防御方法。我们总结了社区的经验教训和取舍,以确保对DNNN模型预测作出有力的解释。