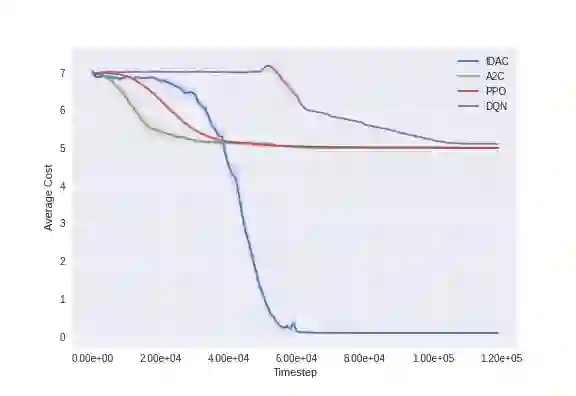
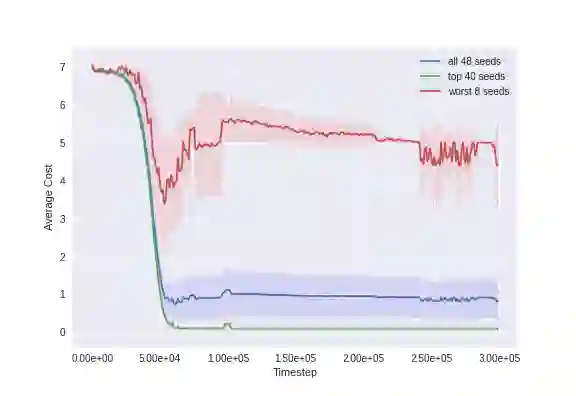
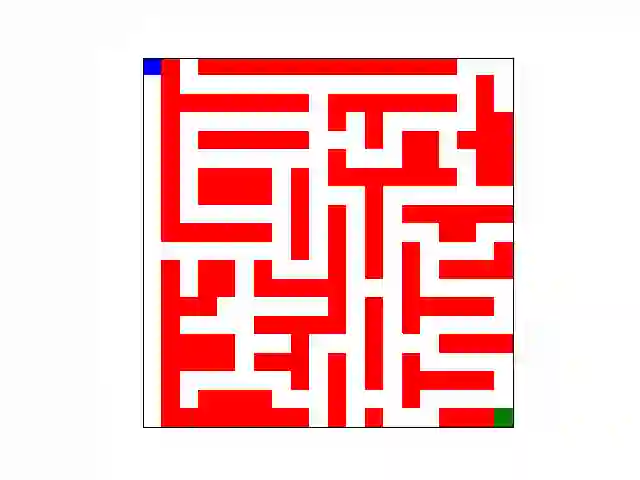
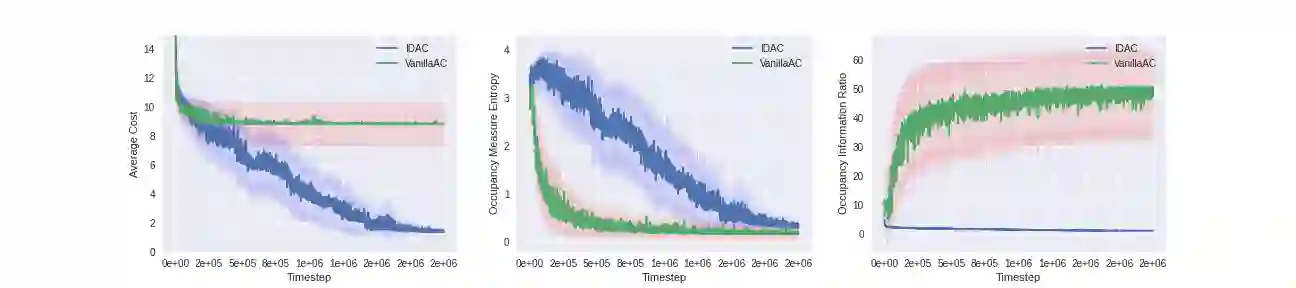
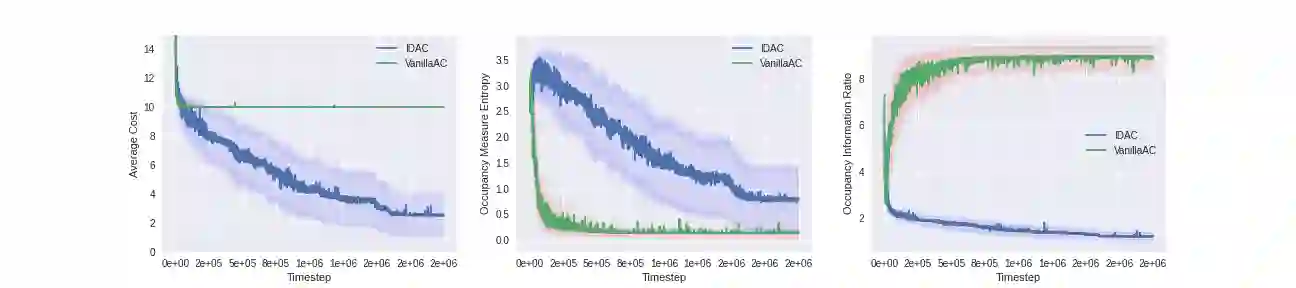
We develop a new measure of the exploration/exploitation trade-off in infinite-horizon reinforcement learning problems called the occupancy information ratio (OIR), which is comprised of a ratio between the infinite-horizon average cost of a policy and the entropy of its long-term state occupancy measure. The OIR ensures that no matter how many trajectories an RL agent traverses or how well it learns to minimize cost, it maintains a healthy skepticism about its environment, in that it defines an optimal policy which induces a high-entropy occupancy measure. Different from earlier information ratio notions, OIR is amenable to direct policy search over parameterized families, and exhibits hidden quasiconcavity through invocation of the perspective transformation. This feature ensures that under appropriate policy parameterizations, the OIR optimization problem has no spurious stationary points, despite the overall problem's nonconvexity. We develop for the first time policy gradient and actor-critic algorithms for OIR optimization based upon a new entropy gradient theorem, and establish both asymptotic and non-asymptotic convergence results with global optimality guarantees. In experiments, these methodologies outperform several deep RL baselines in problems with sparse rewards, where many trajectories may be uninformative and skepticism about the environment is crucial to success.
翻译:我们开发了一种测量无穷分层强化学习问题的勘探/开发权衡的新度量,称为占用率(OIR),它由政策无穷分层平均成本与长期国家占用测量值之间的比例组成。OIR确保无论RL代理跨轨多少轨迹,或如何学会如何尽量减少成本,它都会保持对其环境的健康的怀疑,因为它定义了一种最佳政策,导致高渗透性占用度测量。不同于早期的信息比率概念,OIR可以对参数化家庭进行直接的政策搜索,并且通过不考虑观点转变而显示隐藏的近似相近性。这个特征确保,在适当的政策参数化下,OIR优化问题不会有任何虚假的固定点,尽管总的问题不是混杂性。我们首次在新的梯度梯度梯度梯度测量的基础上为 OIR 优化制定了政策梯度和行为者-趋势算法, 并且建立了不具有精确性、不精确性、不精确性、不精确性、不精确性、不精确性的全球实验方法。