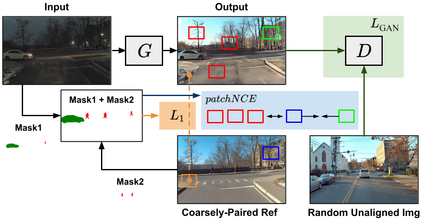
A self-driving car must be able to reliably handle adverse weather conditions (e.g., snowy) to operate safely. In this paper, we investigate the idea of turning sensor inputs (i.e., images) captured in an adverse condition into a benign one (i.e., sunny), upon which the downstream tasks (e.g., semantic segmentation) can attain high accuracy. Prior work primarily formulates this as an unpaired image-to-image translation problem due to the lack of paired images captured under the exact same camera poses and semantic layouts. While perfectly-aligned images are not available, one can easily obtain coarsely-paired images. For instance, many people drive the same routes daily in both good and adverse weather; thus, images captured at close-by GPS locations can form a pair. Though data from repeated traversals are unlikely to capture the same foreground objects, we posit that they provide rich contextual information to supervise the image translation model. To this end, we propose a novel training objective leveraging coarsely-aligned image pairs. We show that our coarsely-aligned training scheme leads to a better image translation quality and improved downstream tasks, such as semantic segmentation, monocular depth estimation, and visual localization.
翻译:自驾驶车必须能够可靠地处理不利的天气条件(如雪雪)才能安全运行。 在本文中, 我们调查了将不良状态下捕获的传感器输入( 图像)转换成无害状态( 阳光阳光) 的想法, 下游任务( 如语义分割) 能够达到很高的精确度 。 先前的工作主要将这设计成一个未受重视的图像到图像翻译的问题, 原因是缺少在同一相机显示和语义布局下拍摄的配对图像 。 虽然无法提供完全接近的图像, 但人们很容易获得非常接近的图像。 例如, 许多人每天在良好和恶劣的天气下行相同的路; 因此, 在接近的全球定位系统地点拍摄的图像可以形成一对配对 。 虽然重复穿梭的数据不太可能捕捉到相同的地面天体物体, 我们假设它们提供了丰富的背景信息来监督图像翻译模型。 为此, 我们提出一个新的培训目标, 利用更精确的相近的图像配对 。 我们展示了我们相近、 质量和视觉分析的图像转换方法, 我们展示了这种深度的图像转换方法,, 以及图像转换为更精确的图像转换方法, 。