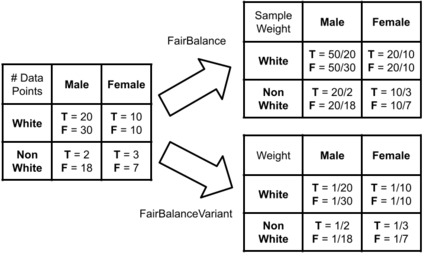
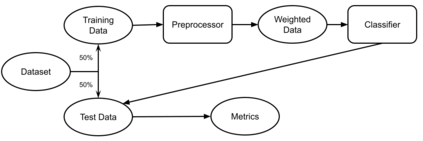
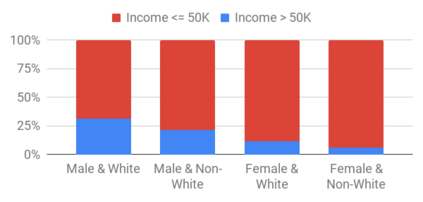
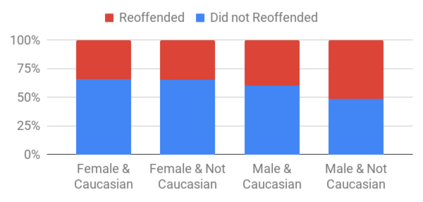
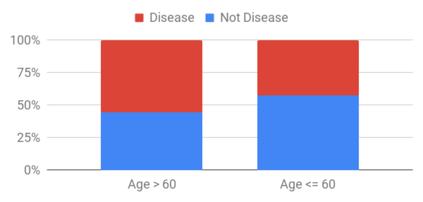
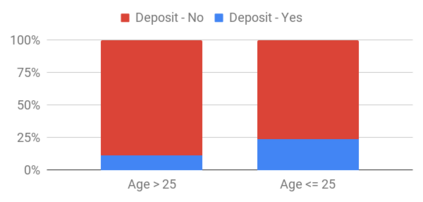
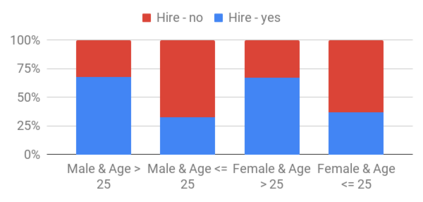
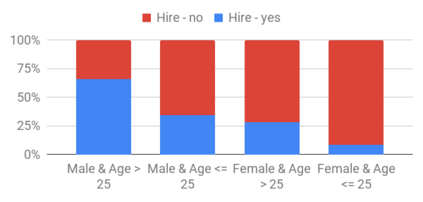
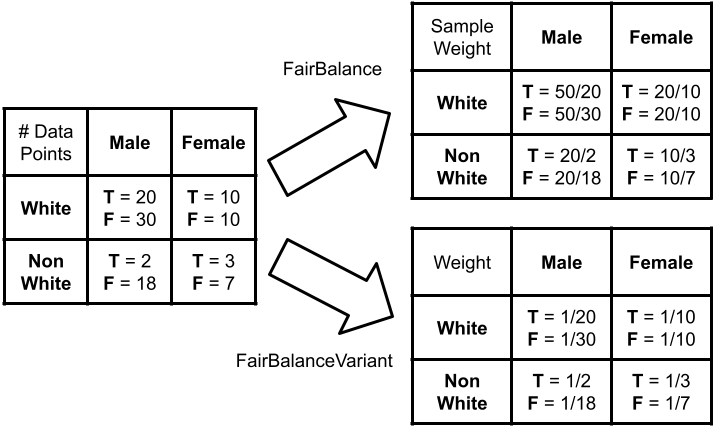
This research seeks to benefit the software engineering society by providing a simple yet effective approach to improve fairness of machine learning software on data with multiple sensitive attributes. Machine learning fairness has attracted increasing attention since machine learning software is increasingly used for high-stakes and high-risk decisions. Amongst all the fairness notations, this work specifically targets "equalized odds". Equalized odds requires that members of every demographic group do not receive disparate mistreatment. It is one of the most widely accepted fairness notations given its advantage in always allowing perfect classifiers. Most existing solutions for machine learning fairness do not directly target equalized odds and only affect one sensitive attribute (e.g. sex) at a time. To overcome this shortage, we analyzed the condition of equalized odds and hypothesize that balancing the class distribution of training data across every demographic group will improve equalized odds of the learned model. On four real-world datasets (two of which have multiple sensitive attributes) and three synthetic datasets, our empirical results show that, at low computational overhead, the proposed preprocessing algorithm FairBalance can significantly improve equalized odds without much, if any damage to the prediction performance. FairBalance also outperforms existing state-of-the-art approaches in terms of equalized odds. To facilitate reuse, reproduction, and validation of this work, our scripts and data are available at https://github.com/hil-se/FairBalance under an open-source Apache license (v2.0).
翻译:这项研究旨在通过提供简单而有效的方法,提高机器学习软件对具有多种敏感属性的数据的公平性,从而让软件工程社会受益。由于机器学习软件越来越多地用于高考量和高风险决策,机器学习的公平性引起了越来越多的关注。在所有公平性评分中,这项工作具体针对的是“公平性差” 。 公平性差要求每个人口群体的成员不受到不同的虐待。这是最广泛接受的公平性评分之一,因为它总能让完美的分类者受益。大多数现有的机器学习公平性办法并不直接针对均等机会,而且只影响到一个敏感属性(如性别)。为了克服这一短缺,我们分析了平衡每个人口群体培训数据班级分布的均等性差数和虚伪性状况,这将改善所学模型的均等性差数。 关于四个真实世界数据集(其中两个具有多种敏感属性)和三个合成数据集,我们的实证结果显示,在低计算性间接费用下,拟议的预处理法公平性比差在一个时间点上可以大大改善均等性差,如果对预测性能造成任何损害的话。