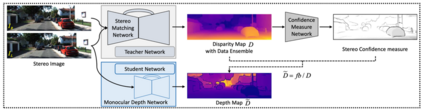
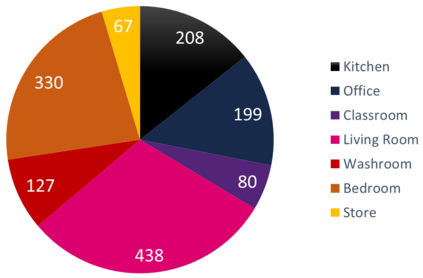
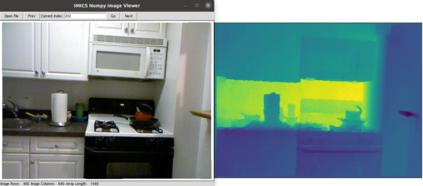
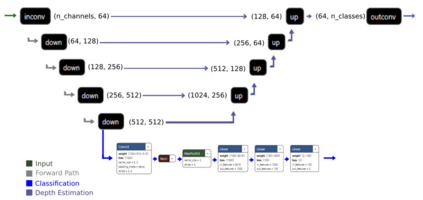
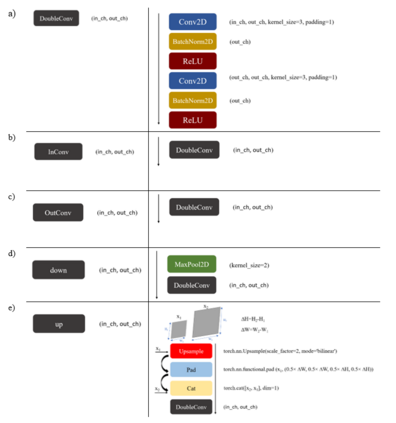
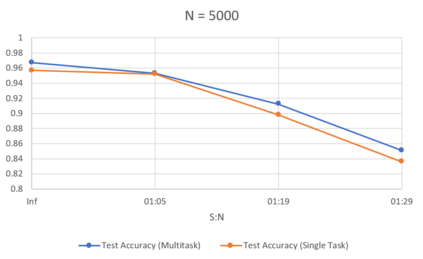
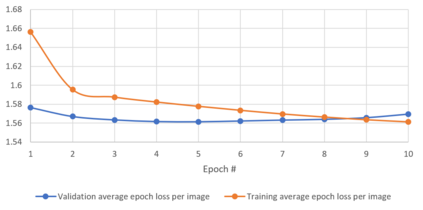
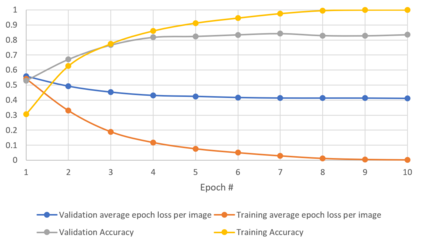
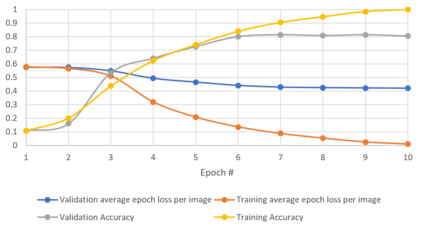
Generalizability is the ultimate goal of Machine Learning (ML) image classifiers, for which noise and limited dataset size are among the major concerns. We tackle these challenges through utilizing the framework of deep Multitask Learning (dMTL) and incorporating image depth estimation as an auxiliary task. On a customized and depth-augmented derivation of the MNIST dataset, we show a) multitask loss functions are the most effective approach of implementing dMTL, b) limited dataset size primarily contributes to classification inaccuracy, and c) depth estimation is mostly impacted by noise. In order to further validate the results, we manually labeled the NYU Depth V2 dataset for scene classification tasks. As a contribution to the field, we have made the data in python native format publicly available as an open-source dataset and provided the scene labels. Our experiments on MNIST and NYU-Depth-V2 show dMTL improves generalizability of the classifiers when the dataset is noisy and the number of examples is limited.
翻译:通用性是机器学习(ML)图像分类的最终目的,对此,噪音和有限的数据集大小是主要关注事项之一。我们通过利用深多任务学习(dMTL)框架和将图像深度估算作为一项辅助任务来应对这些挑战。在对MNIST数据集进行定制和深度强化衍生的过程中,我们显示a)多任务损失功能是执行dMTL的最有效方法,b)有限的数据集大小主要造成分类不准确性,c)深度估计大多受到噪音的影响。为了进一步验证结果,我们手工将NYU深度V2数据集标为现场分类任务。作为对实地工作的贡献,我们以python本地格式提供的数据,作为公开源数据集公开提供,并提供现场标签。我们在MNIST和NYU-Depah-V2的实验显示dMTL提高了分类人员在数据集噪音和实例数量有限时的通用性。