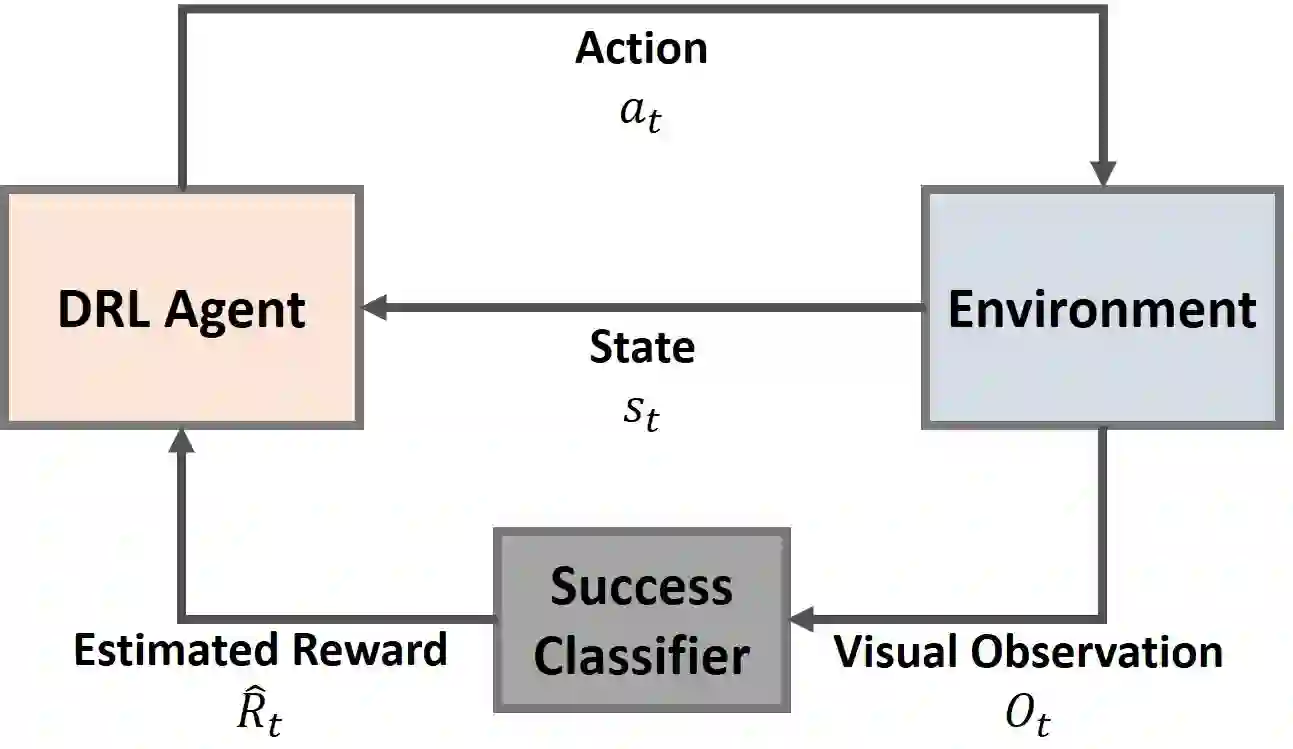
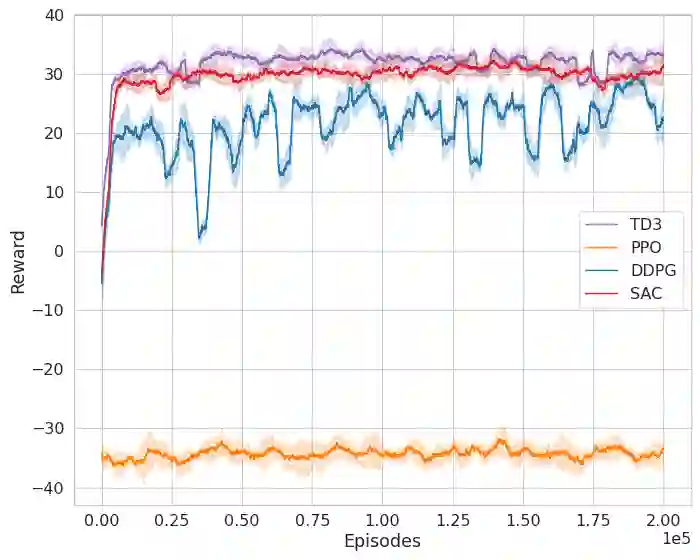
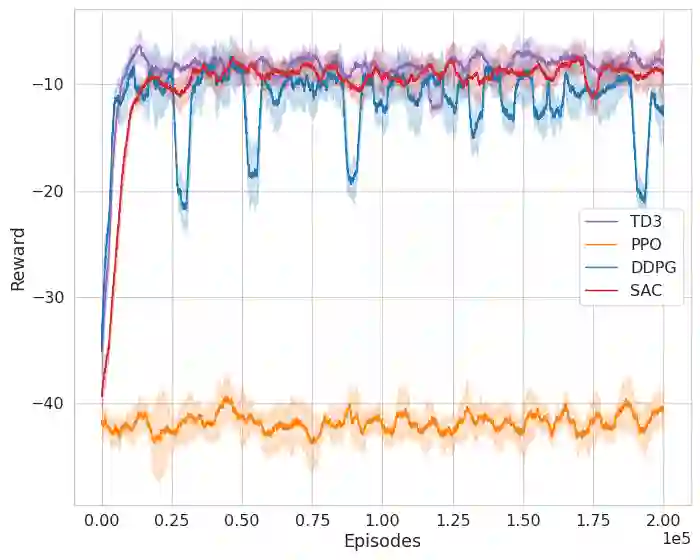
Deep Reinforcement Learning (DRL) is a promising approach for teaching robots new behaviour. However, one of its main limitations is the need for carefully hand-coded reward signals by an expert. We argue that it is crucial to automate the reward learning process so that new skills can be taught to robots by their users. To address such automation, we consider task success classifiers using visual observations to estimate the rewards in terms of task success. In this work, we study the performance of multiple state-of-the-art deep reinforcement learning algorithms under different types of reward: Dense, Sparse, Visual Dense, and Visual Sparse rewards. Our experiments in various simulation tasks (Pendulum, Reacher, Pusher, and Fetch Reach) show that while DRL agents can learn successful behaviours using visual rewards when the goal targets are distinguishable, their performance may decrease if the task goal is not clearly visible. Our results also show that visual dense rewards are more successful than visual sparse rewards and that there is no single best algorithm for all tasks.
翻译:深度强化学习(DRL)是教授机器人新行为的一种很有希望的方法。 但是,它的主要局限性之一是需要一位专家仔细使用手工编码的奖赏信号。 我们认为,将奖赏学习过程自动化,以便其用户能够向机器人传授新的技能至关重要。 解决这种自动化问题,我们认为任务成功分类者使用视觉观察来估计任务成功与否的奖赏。 在这项工作中,我们研究了不同奖赏类型下多种最先进的高超强化学习算法的绩效: Dense, Sprass, Vision Dense, 和视觉微缩奖赏。 我们在各种模拟任务( Pendulum, Reacher, Pusher, and Fetch Reach Reach)中进行的实验显示,虽然DRL代理者可以使用视觉奖赏来学习成功的行为,但是如果任务目标不明显可见,其业绩可能会下降。 我们的结果还表明,视觉密集的奖励比视觉微弱奖赏更成功,并且没有对所有任务进行单一的最佳算法。