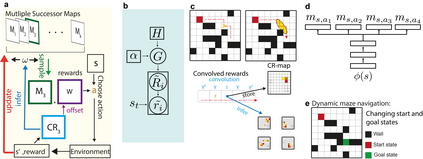
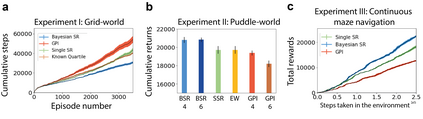
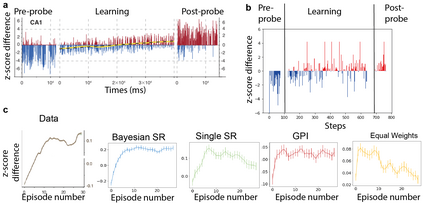
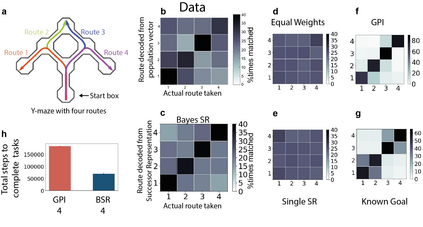
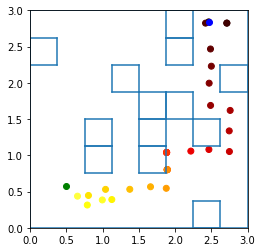
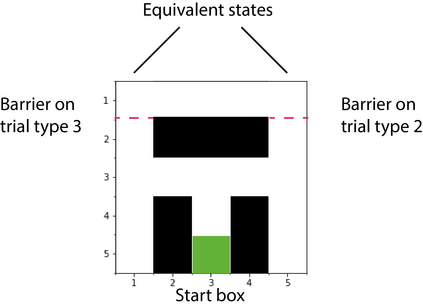
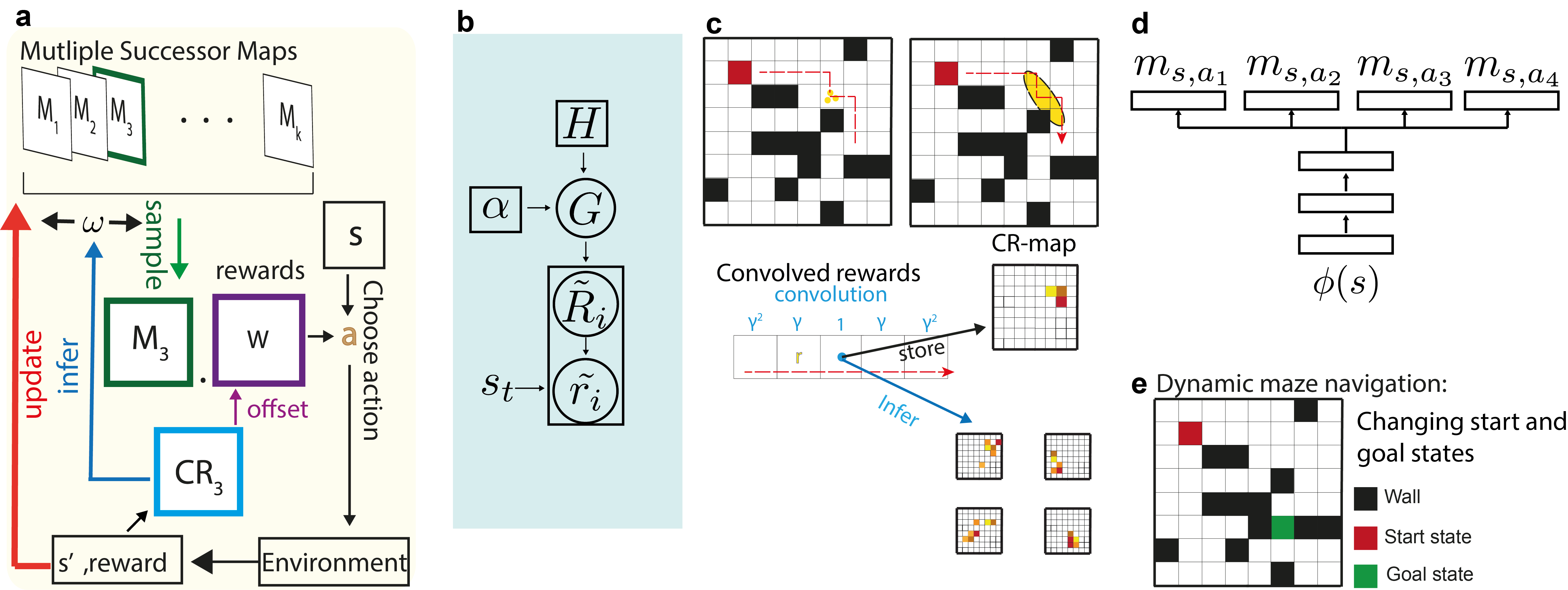
Humans and animals show remarkable flexibility in adjusting their behaviour when their goals, or rewards in the environment change. While such flexibility is a hallmark of intelligent behaviour, these multi-task scenarios remain an important challenge for machine learning algorithms and neurobiological models alike. Factored representations can enable flexible behaviour by abstracting away general aspects of a task from those prone to change, while nonparametric methods provide a principled way of using similarity to past experiences to guide current behaviour. Here we combine the successor representation (SR), that factors the value of actions into expected outcomes and corresponding rewards, with evaluating task similarity through nonparametric inference and clustering the space of rewards. The proposed algorithm improves SR's transfer capabilities by inverting a generative model over tasks, while also explaining important neurobiological signatures of place cell representation in the hippocampus. It dynamically samples from a flexible number of distinct SR maps while accumulating evidence about the current reward context, and outperforms competing algorithms in settings with both known and unsignalled rewards changes. It reproduces the "flickering" behaviour of hippocampal maps seen when rodents navigate to changing reward locations, and gives a quantitative account of trajectory-dependent hippocampal representations (so-called splitter cells) and their dynamics. We thus provide a novel algorithmic approach for multi-task learning, as well as a common normative framework that links together these different characteristics of the brain's spatial representation.
翻译:人类和动物在目标或环境变化中的回报时,在调整行为时表现出显著的灵活性。虽然这种灵活性是智能行为的一个标志,但这些多任务情景对于机器学习算法和神经生物模型都是一项重大挑战。 分量表可以通过从容易变化的人群中抽取任务的一般方面,使灵活的行为变得灵活,而非分量方法则提供了一种原则性的方法,利用与过去经验相似的相似性来指导当前行为。 在这里,我们将后续代表制(SR)结合起来,将行动的价值纳入预期结果和相应的回报,同时通过非对称推论来评估任务相似性,并将奖励的空间空间组合起来。提议的算法提高了SR的转移能力,在任务上颠倒一种基因模型,同时也解释了在河马运动运动中将细胞代表处的一些重要的神经生物学特征。 它以动态方式从灵活数量的SR地图中提取样本,同时积累了当前奖赏背景的证据,并超越了在已知和未指派的奖赏框架环境中的相互竞争的运算法。 它复制了在混合的河马运动地图上所看到的“滑动”行为, 以及“我们不断移动的大脑动态模型”,从而提供了一种不同的轨动的轨迹,从而提供了一种不同的学习模式的分级图。