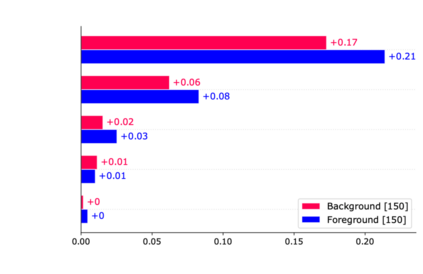
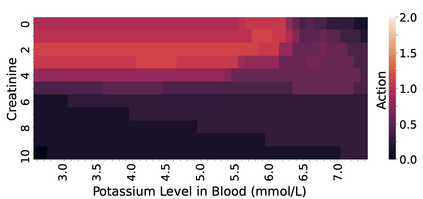
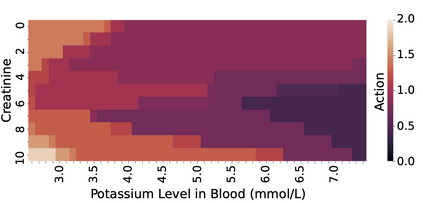
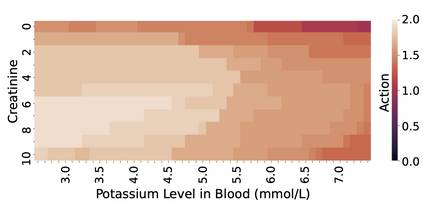
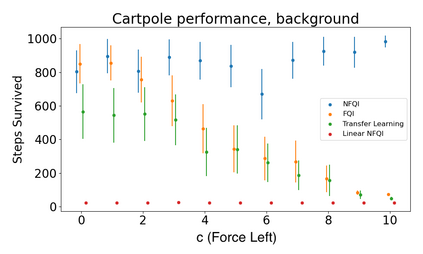
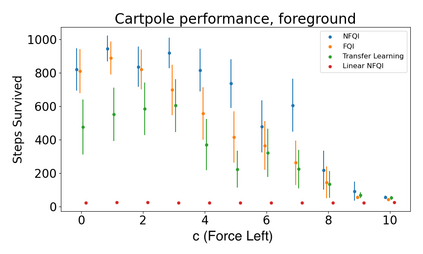
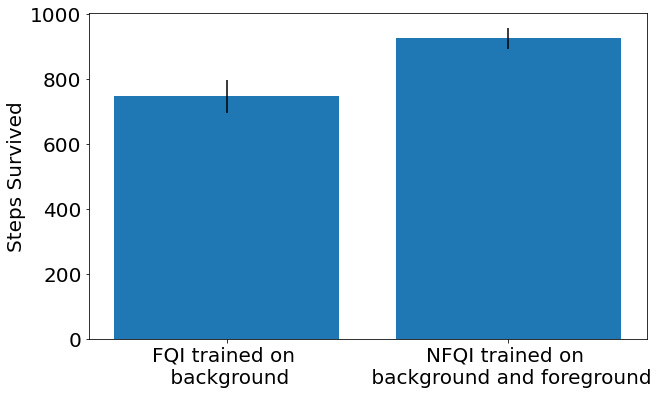
Off-policy reinforcement learning (RL) has proven to be a powerful framework for guiding agents' actions in environments with stochastic rewards and unknown or noisy state dynamics. In many real-world settings, these agents must operate in multiple environments, each with slightly different dynamics. For example, we may be interested in developing policies to guide medical treatment for patients with and without a given disease, or policies to navigate curriculum design for students with and without a learning disability. Here, we introduce nested policy fitted Q-iteration (NFQI), an RL framework that finds optimal policies in environments that exhibit such a structure. Our approach develops a nested $Q$-value function that takes advantage of the shared structure between two groups of observations from two separate environments while allowing their policies to be distinct from one another. We find that NFQI yields policies that rely on relevant features and perform at least as well as a policy that does not consider group structure. We demonstrate NFQI's performance using an OpenAI Gym environment and a clinical decision making RL task. Our results suggest that NFQI can develop policies that are better suited to many real-world clinical environments.
翻译:强化政策外学习(RL)已被证明是一个强有力的框架,用以指导代理人在具有随机性奖赏和未知或噪音状态动态的环境中采取行动。在许多现实世界环境中,这些代理人必须在多种环境中运作,每个环境的动态略有不同。例如,我们可能有兴趣制定政策,指导对有特定疾病和没有特定疾病的病人的治疗,或制定为有学习残疾和没有学习残疾的学生制定课程设计的政策。在这里,我们引入了符合Qitenation(NFQI)的嵌套政策(NFQI),这是一个在展示这种结构的环境中找到最佳政策的RL框架。我们的方法开发了一个嵌套的美元价值功能,利用两个不同环境的两组观察组之间的共享结构,同时允许其政策与另一个不同。我们发现NFQI产生的政策依赖于相关特点,至少不考虑群体结构的政策。我们用OpenAI Gym环境和临床决策任务来展示NFQI的表现。我们的结果表明,NFQI可以制定更适合许多现实临床环境的政策。