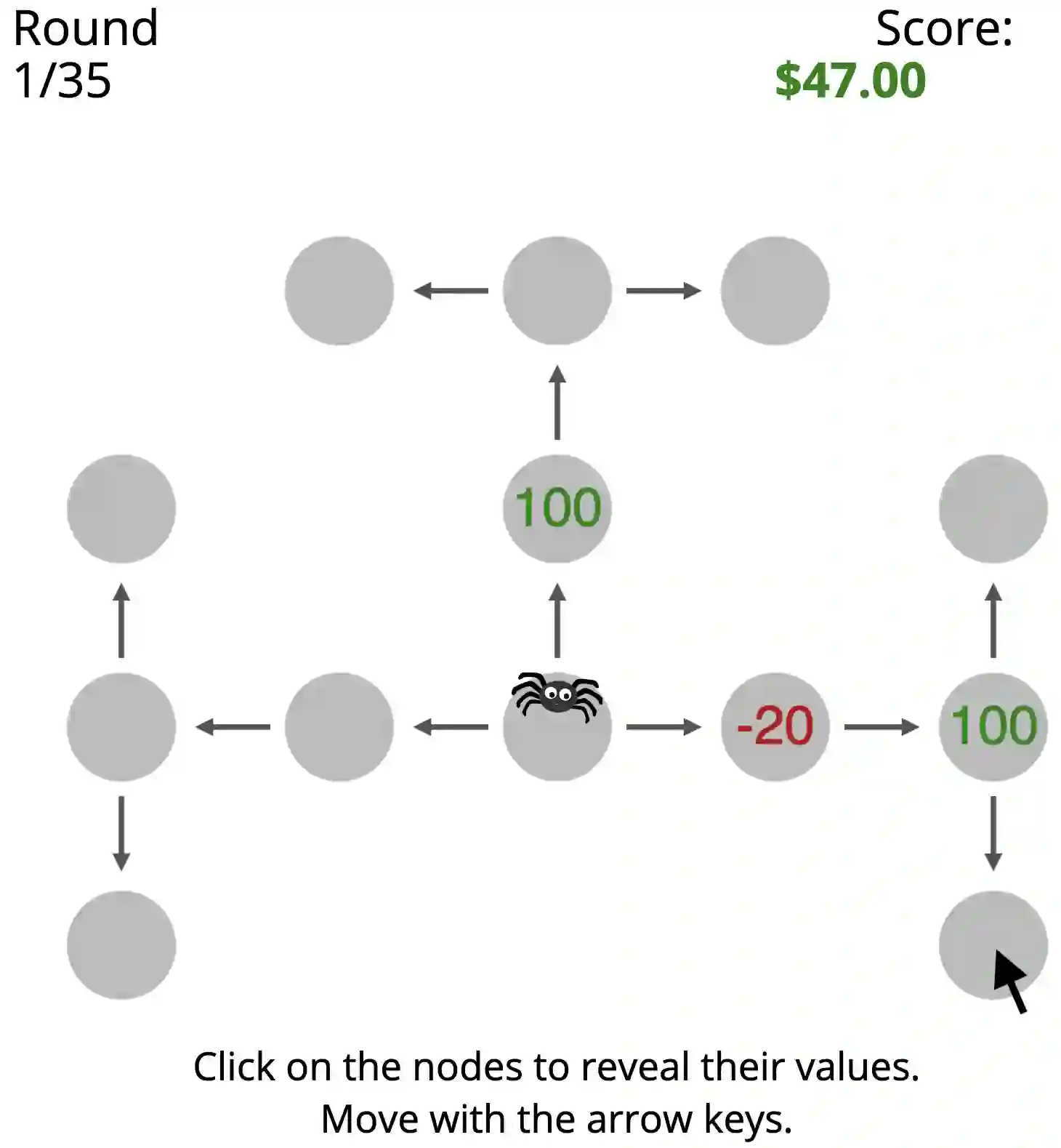
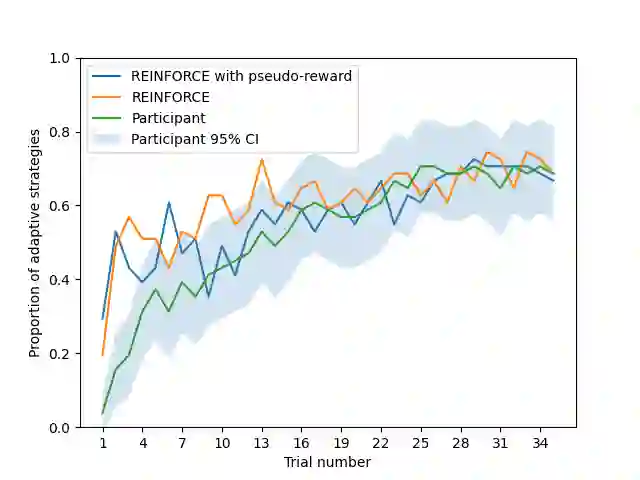
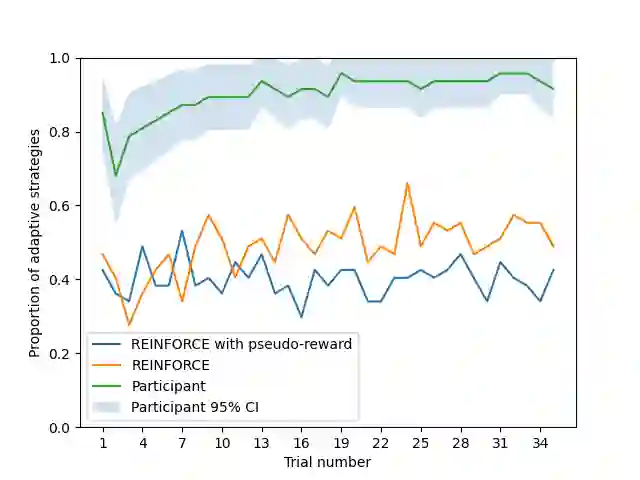
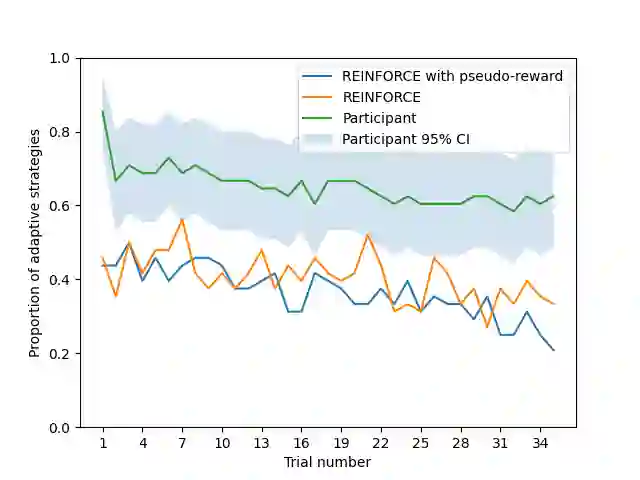
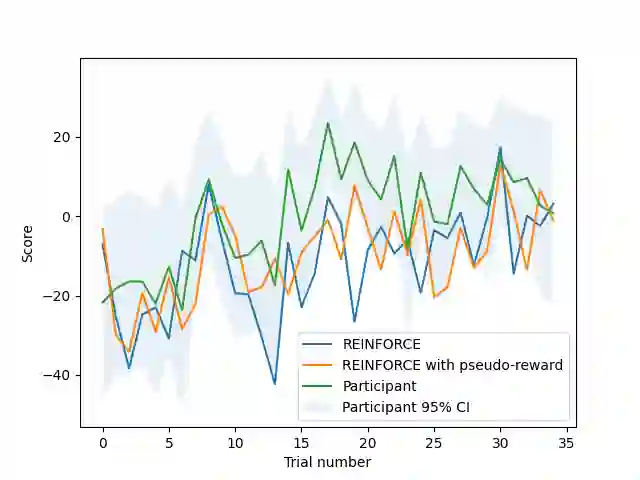
How is it that humans can solve complex planning tasks so efficiently despite limited cognitive resources? One reason is its ability to know how to use its limited computational resources to make clever choices. We postulate that people learn this ability from trial and error (metacognitive reinforcement learning). Here, we systematize models of the underlying learning mechanisms and enhance them with more sophisticated additional mechanisms. We fit the resulting 86 models to human data collected in previous experiments where different phenomena of metacognitive learning were demonstrated and performed Bayesian model selection. Our results suggest that a gradient ascent through the space of cognitive strategies can explain most of the observed qualitative phenomena, and is therefore a promising candidate for explaining the mechanism underlying metacognitive learning.
翻译:人类如何在认知资源有限的情况下能够如此高效地解决复杂的规划任务?一个原因是,人类有能力知道如何利用其有限的计算资源作出明智的选择。我们假设人们从试验和错误中学习这种能力(混合强化学习 ) 。在这里,我们将基础学习机制模型系统化,并用更先进的额外机制加强这些模型。我们把由此产生的86个模型与以往实验中收集的人类数据相匹配,这些实验展示了不同的元认知学习现象,并进行了巴耶斯模式选择。我们的结果表明,通过认知战略空间的梯度增益可以解释大多数观察到的质量现象,因此,我们是解释元认知学习机制的有希望的候选者。