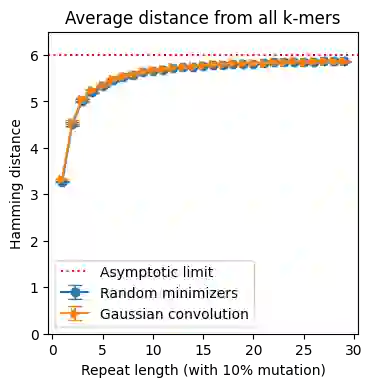
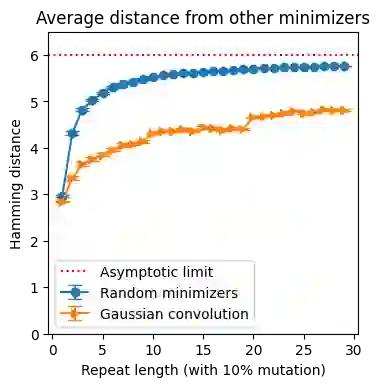
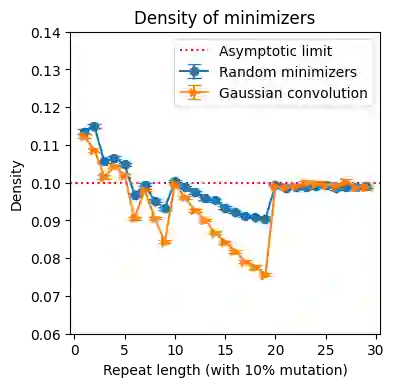
Minimizers and convolutional neural networks (CNNs) are two quite distinct popular techniques that have both been employed to analyze categorical biological sequences. At face value, the methods seem entirely dissimilar. Minimizers use min-wise hashing on a rolling window to extract a single important k-mer feature per window. CNNs start with a wide array of randomly initialized convolutional filters, paired with a pooling operation, and then multiple additional neural layers to learn both the filters themselves and how those filters can be used to classify the sequence. In this manuscript, we demonstrate through a careful mathematical analysis of hash function properties that for sequences over a categorical alphabet, random Gaussian initialization of convolutional filters with max-pooling is equivalent to choosing a minimizer ordering such that selected k-mers are (in Hamming distance) far from the k-mers within the sequence but close to other minimizers. In empirical experiments, we find that this property manifests as decreased density in repetitive regions, both in simulation and on real human telomeres. This provides a partial explanation for the effectiveness of CNNs in categorical sequence analysis.
翻译:最小化器和进化神经网络(CNNs)是两种截然不同的流行技术,两者都用来分析绝对生物序列。 在表面值上,方法似乎完全不同。 最小化器在滚动窗口上使用微小散射法来提取每个窗口的单一重要的 k- mer 特性。 CNN 开始时使用一系列随机初始化的共变过滤器, 并配有集合操作, 然后多层神经层来学习过滤器本身以及如何使用这些过滤器来分类序列。 在本手稿中, 我们通过仔细的对散列函数特性的数学分析来显示, 对于绝对字母上的序列, 随机初始化带最大集合的共变过滤器相当于选择一个最小化器, 命令选中的 k- mers 在序列中距离 k- mers 距离 k- mers( Hamming 距离) 距离 k- mers( 距离) 较远, 但距离其他最小化器更近。 在实验中, 我们发现这种属性表现为重复区域的密度降低, 包括模拟和真实的人类调色谱分析。 这为部分解释 。