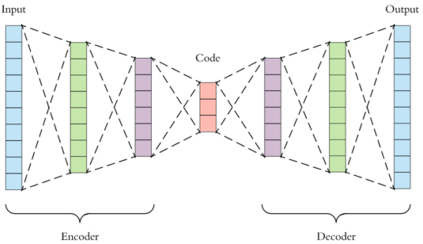
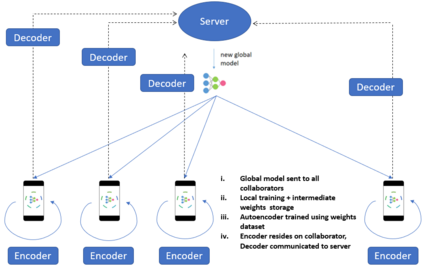
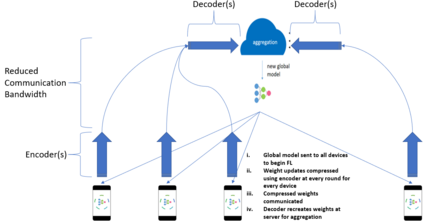
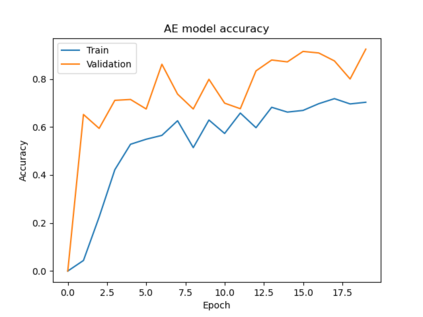
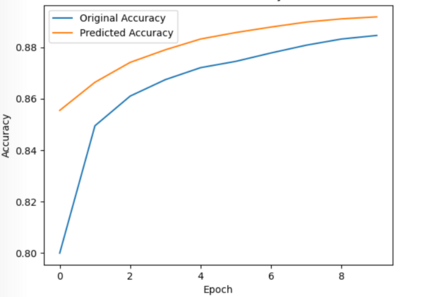
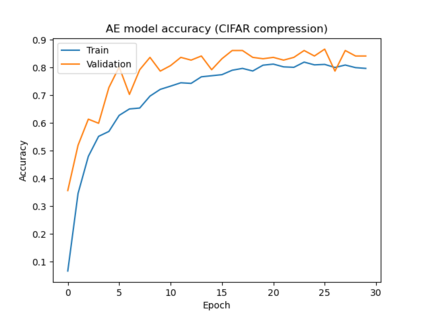
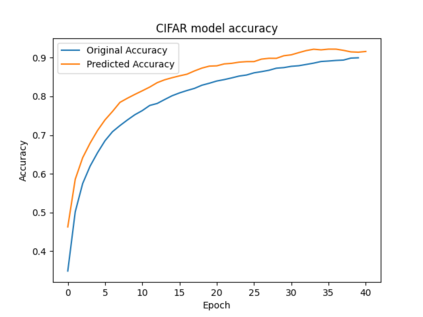
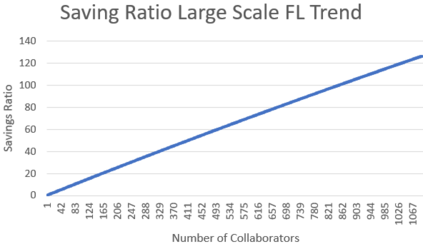
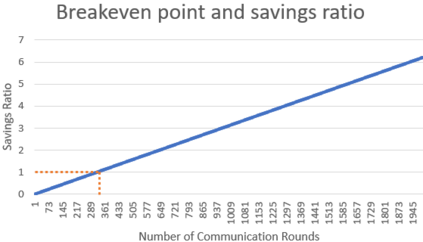
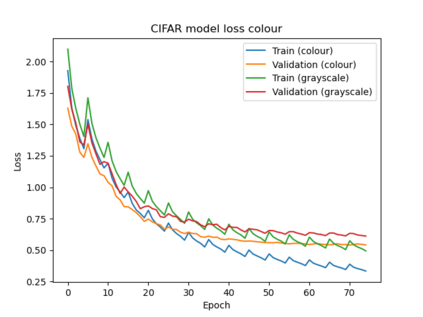
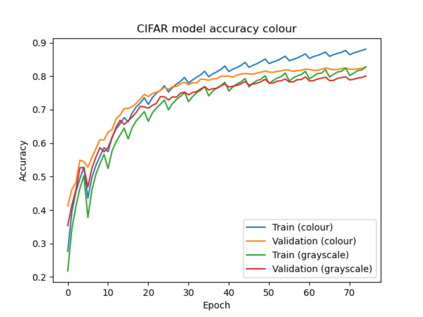
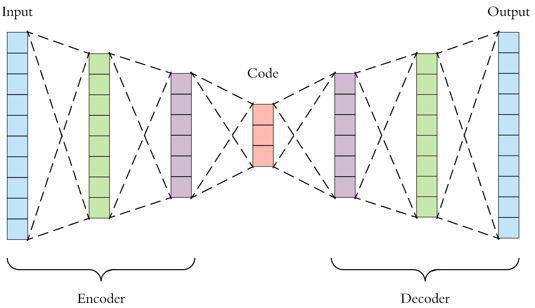
Federated Learning (FL) solves many of this decade's concerns regarding data privacy and computation challenges. FL ensures no data leaves its source as the model is trained at where the data resides. However, FL comes with its own set of challenges. The communication of model weight updates in this distributed environment comes with significant network bandwidth costs. In this context, we propose a mechanism of compressing the weight updates using Autoencoders (AE), which learn the data features of the weight updates and subsequently perform compression. The encoder is set up on each of the nodes where the training is performed while the decoder is set up on the node where the weights are aggregated. This setup achieves compression through the encoder and recreates the weights at the end of every communication round using the decoder. This paper shows that the dynamic and orthogonal AE based weight compression technique could serve as an advantageous alternative (or an add-on) in a large scale FL, as it not only achieves compression ratios ranging from 500x to 1720x and beyond, but can also be modified based on the accuracy requirements, computational capacity, and other requirements of the given FL setup.
翻译:联邦学习联盟(FL) 解决了本十年中许多关于数据隐私和计算挑战的担忧。 FL 确保数据不会离开源头,因为模型是在数据所在地接受培训的。 但是, FL 带来自己的一系列挑战。 在这个分布环境中, 模型重量更新的交流会带来巨大的网络带宽成本。 在这方面, 我们提出一个机制, 使用Autoencoders(AE) 压缩重量更新( AE) 压缩, 了解重量更新的数据特征, 并随后进行压缩。 编码器设置在进行培训的每个节点上, 而解码器则设置在重量汇总的节点上。 这种设置通过编码器实现压缩, 并用解码器重新生成每轮通信回合结尾的重量。 本文显示, 动态和孔径AE 重量压缩技术可以作为大规模FL 的有利替代品( 或附加), 因为它不仅达到500x 至 1720x 及以后的压缩比率, 还可以根据给定的FL 的准确性要求、 计算能力和其他要求进行修改 。