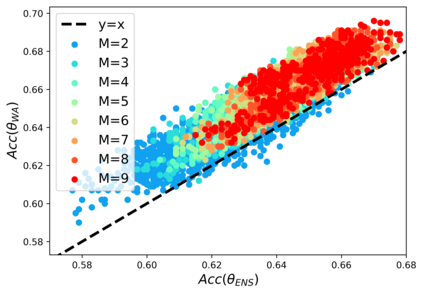
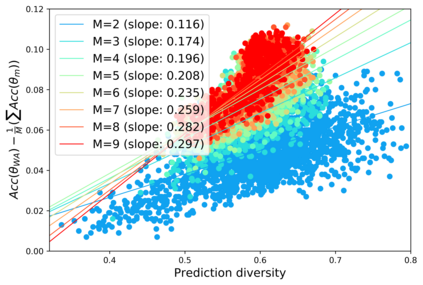
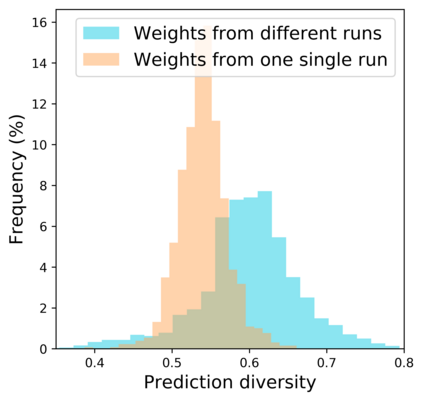
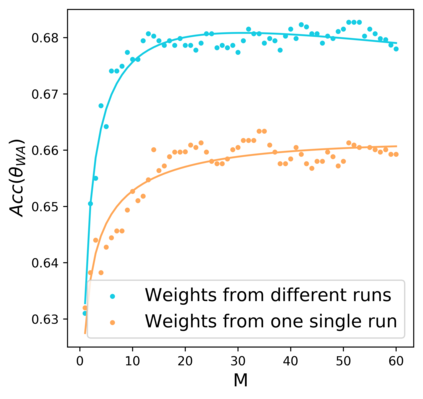
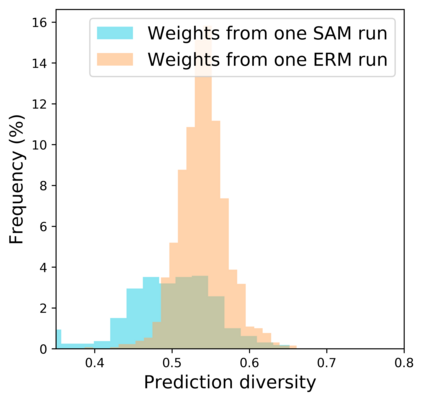
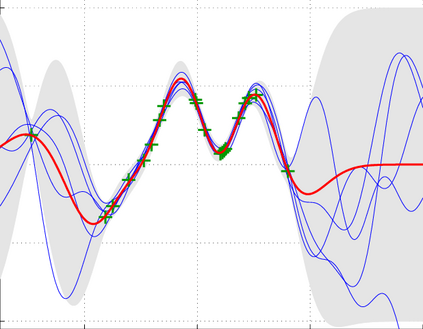
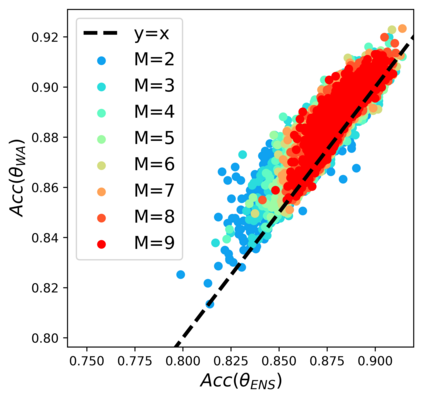
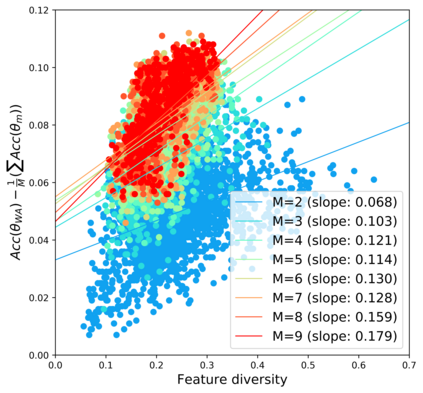
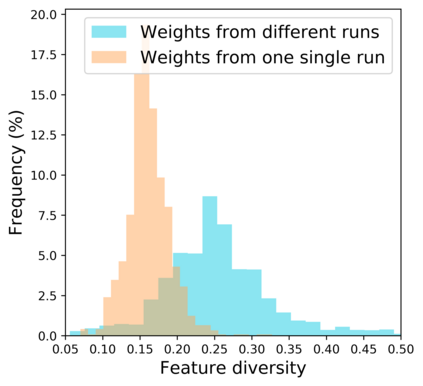
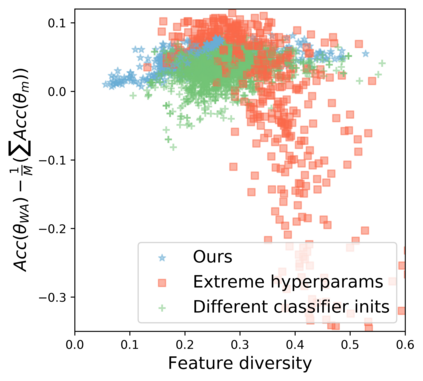
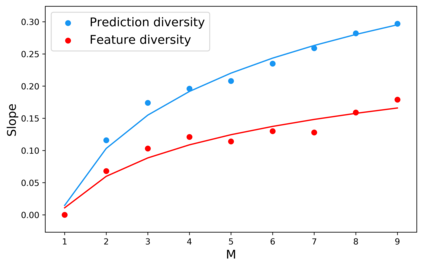
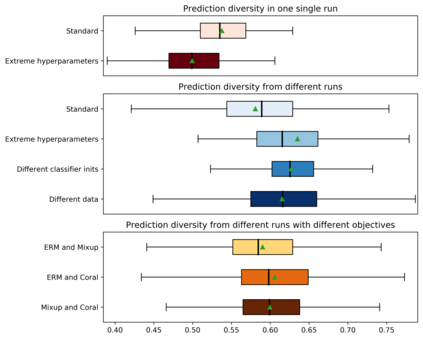
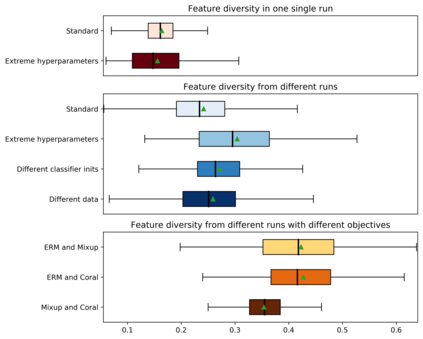
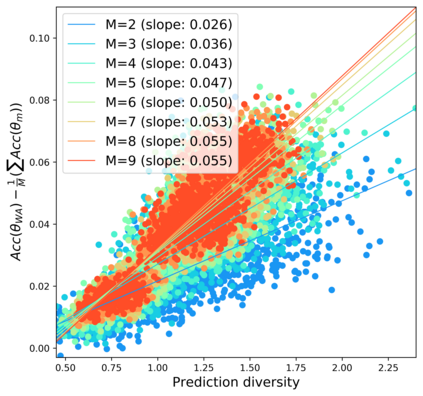
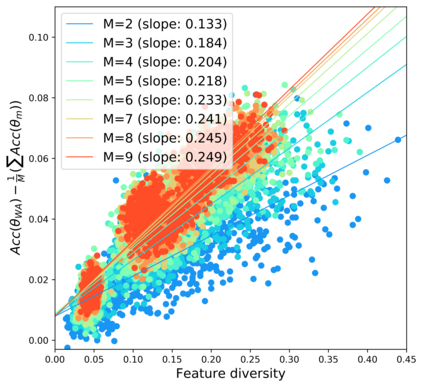
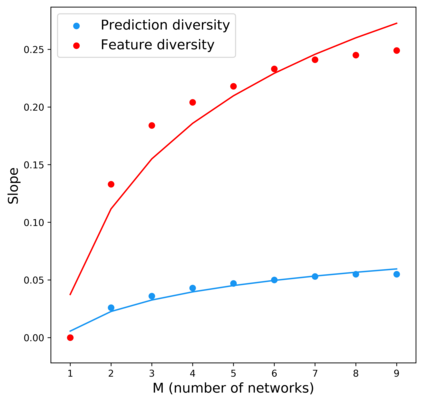
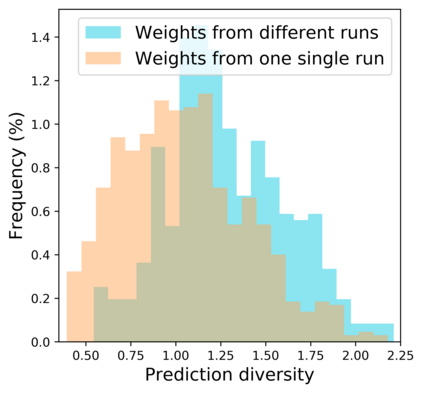
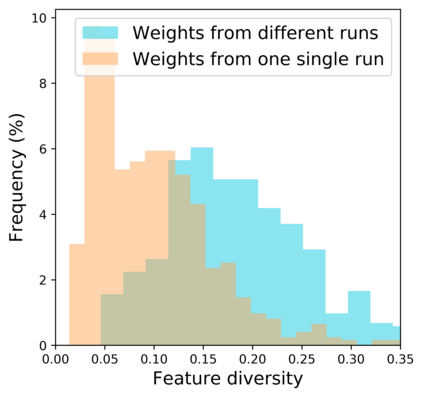
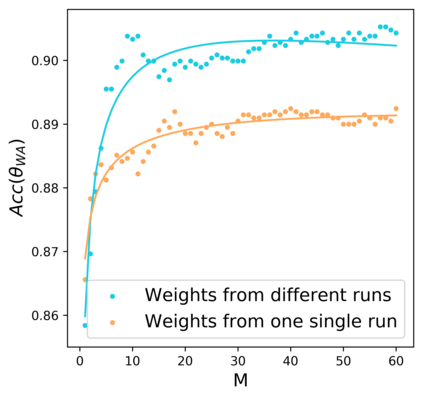
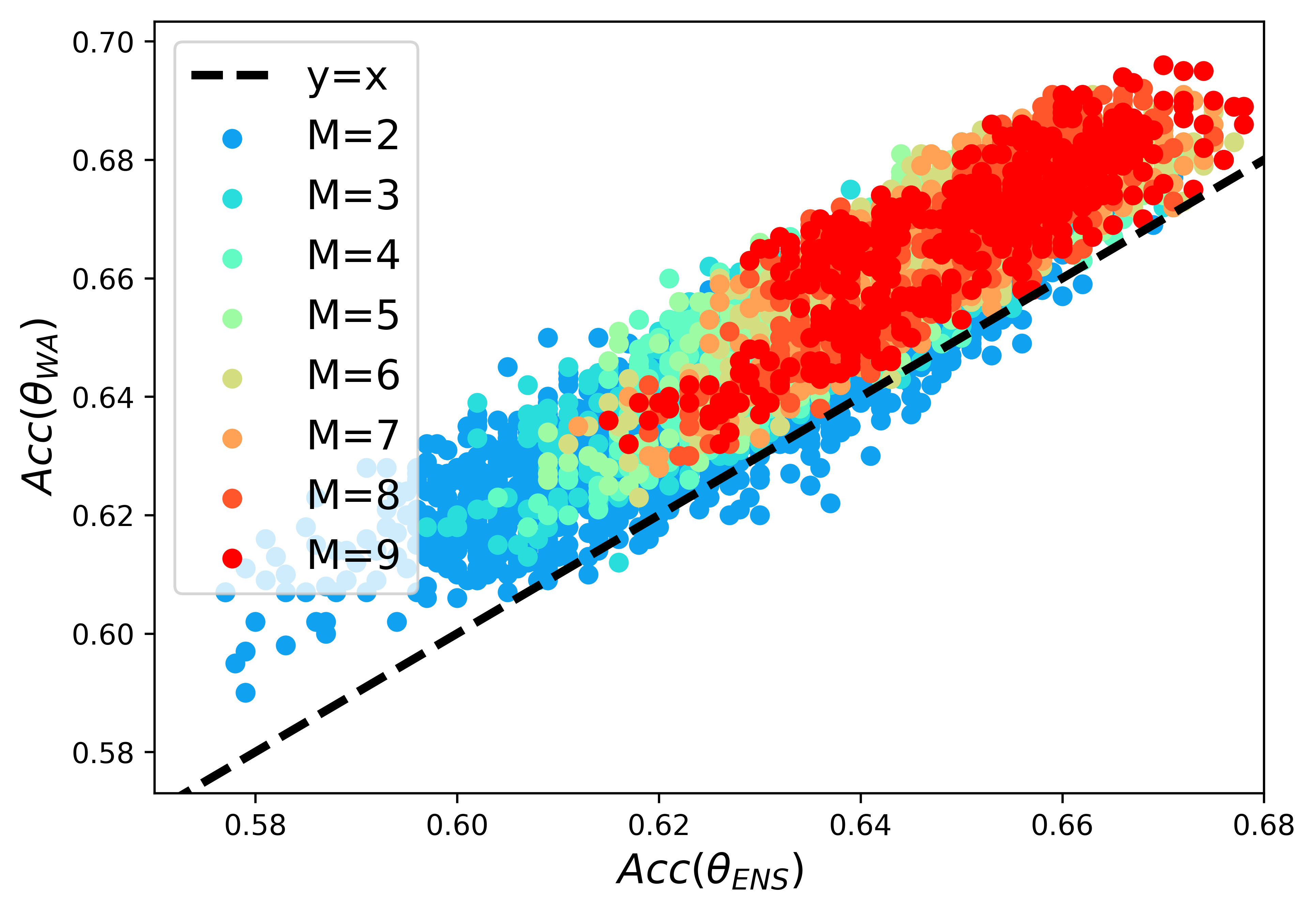
Standard neural networks struggle to generalize under distribution shifts. For out-of-distribution generalization in computer vision, the best current approach averages the weights along a training run. In this paper, we propose Diverse Weight Averaging (DiWA) that makes a simple change to this strategy: DiWA averages the weights obtained from several independent training runs rather than from a single run. Perhaps surprisingly, averaging these weights performs well under soft constraints despite the network's nonlinearities. The main motivation behind DiWA is to increase the functional diversity across averaged models. Indeed, models obtained from different runs are more diverse than those collected along a single run thanks to differences in hyperparameters and training procedures. We motivate the need for diversity by a new bias-variance-covariance-locality decomposition of the expected error, exploiting similarities between DiWA and standard functional ensembling. Moreover, this decomposition highlights that DiWA succeeds when the variance term dominates, which we show happens when the marginal distribution changes at test time. Experimentally, DiWA consistently improves the state of the art on the competitive DomainBed benchmark without inference overhead.
翻译:标准神经网络在分布变化中难以普及。 对于计算机视野的分布性一般化, 最佳的当前方法在培训运行过程中平均加权数。 在本文中, 我们提议“ 不同体重变化( DIWA) ”, 简单改变这一战略: DIWA 平均从数个独立培训运行中获得的加权数, 而不是一次运行。 也许令人惊讶的是, 平均这些加权数在软约束下表现良好, 尽管网络没有线性。 DIWA 背后的主要动机是增加平均模型的功能多样性。 事实上, 不同运行中获得的模型比单运行中收集的模型要多样化得多, 因为超参数和培训程序的差异。 我们通过新的偏差差异- 差异- 差异- 差异- 本地化来激励多样性的需要, 利用 DIWA 和标准功能组合之间的相似性。 此外, 这一分解突出显示, 当差异性术语在测试时会成功, 我们所显示的是当边际分布变化时, 。 实验性地, DWA 持续改善竞争性的DOB 基准的艺术状况。