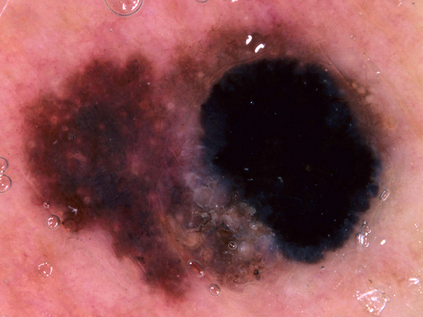
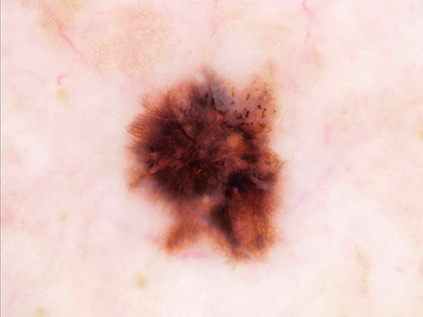
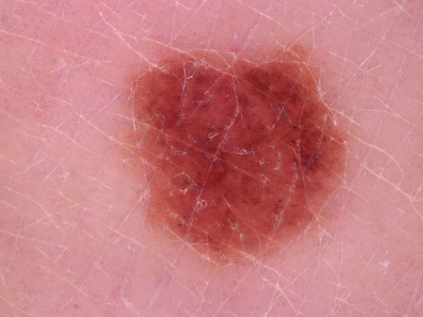
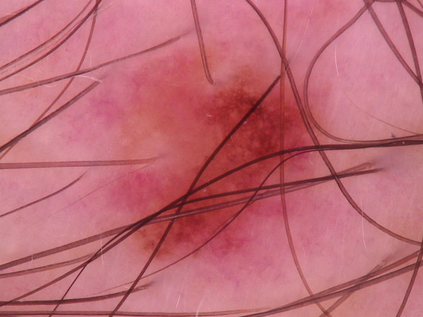
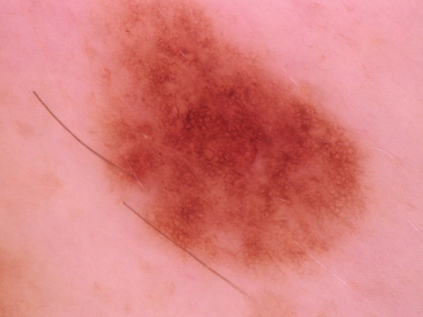
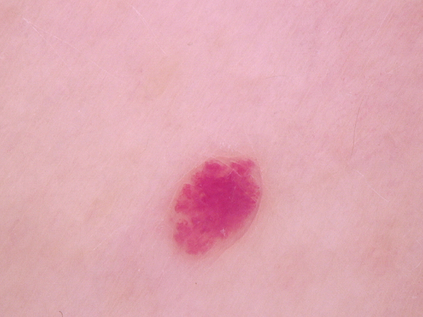
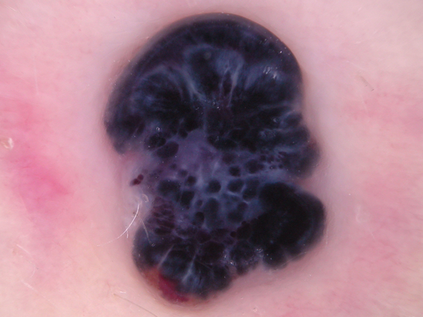
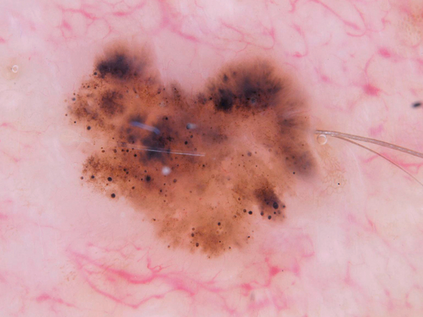
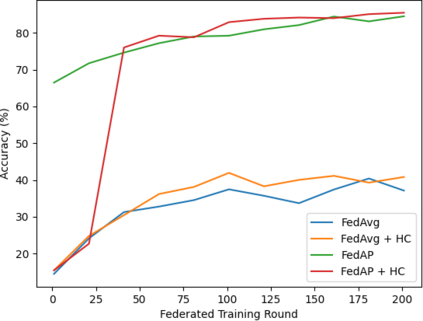
Federated learning (FL) is a distributed learning method that offers medical institutes the prospect of collaboration in a global model while preserving the privacy of their patients. Although most medical centers conduct similar medical imaging tasks, their differences, such as specializations, number of patients, and devices, lead to distinctive data distributions. Data heterogeneity poses a challenge for FL and the personalization of the local models. In this work, we investigate an adaptive hierarchical clustering method for FL to produce intermediate semi-global models, so clients with similar data distribution have the chance of forming a more specialized model. Our method forms several clusters consisting of clients with the most similar data distributions; then, each cluster continues to train separately. Inside the cluster, we use meta-learning to improve the personalization of the participants' models. We compare the clustering approach with classical FedAvg and centralized training by evaluating our proposed methods on the HAM10k dataset for skin lesion classification with extreme heterogeneous data distribution. Our experiments demonstrate significant performance gain in heterogeneous distribution compared to standard FL methods in classification accuracy. Moreover, we show that the models converge faster if applied in clusters and outperform centralized training while using only a small subset of data.
翻译:联邦学习(FL)是一种分布式学习方法,它为医疗机构提供了在全球模式中合作的前景,同时保护其病人的隐私。虽然大多数医疗中心都执行类似的医疗成像任务,但其不同之处,如专业、病人人数和装置等,导致了独特的数据分布。数据差异性对FL和地方模型的个性化构成了挑战。在这项工作中,我们调查了FL的适应性等级分组方法,以产生中间半全球模型,因此,拥有类似数据的客户有机会形成一个更加专业化的模式。我们的方法组成了若干组群,由数据分布最相似的客户组成;然后,每个组群继续单独培训。在组内,我们利用元学习来改进参与者模型的个人化。我们通过评估我们提议的皮肤病分类HAM10k数据集的方法和极端多元性数据分布,将集群方法与传统的FedAvg和集中化培训进行比较。我们的实验表明,与分类精度方面标准的FL方法相比,异性分布获得显著的绩效。此外,我们显示,如果这些模型在组群集和超越集中化培训中应用,我们只使用一个小组数据,那么这些模型就会更快地结合。