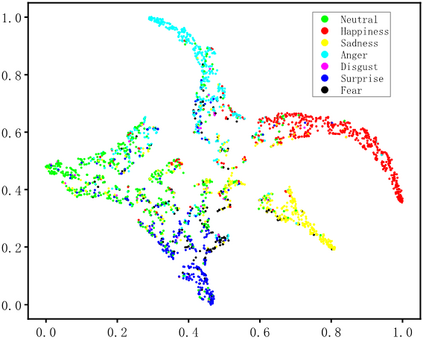
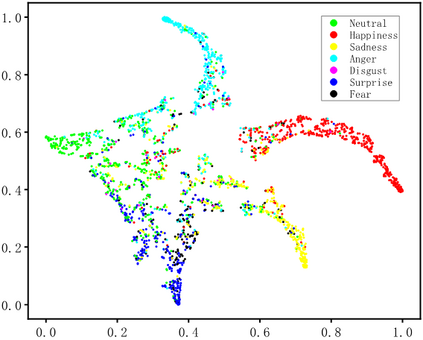
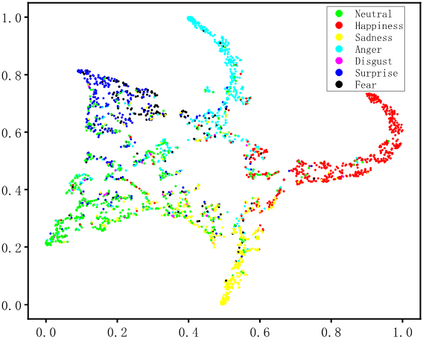
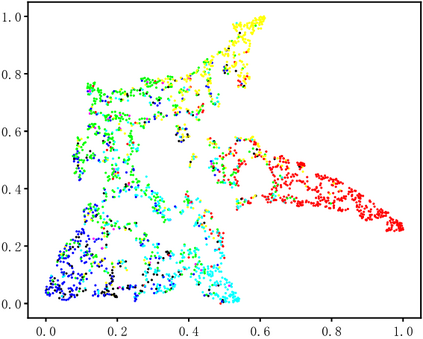
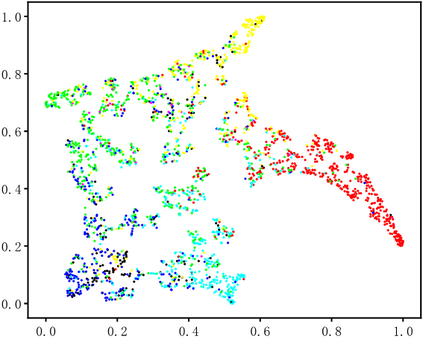
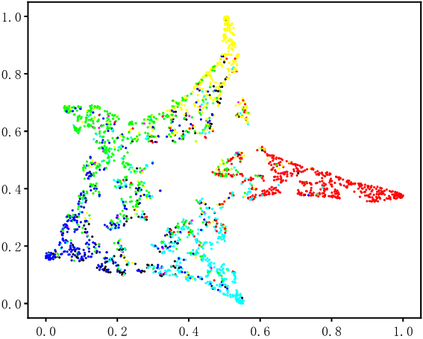
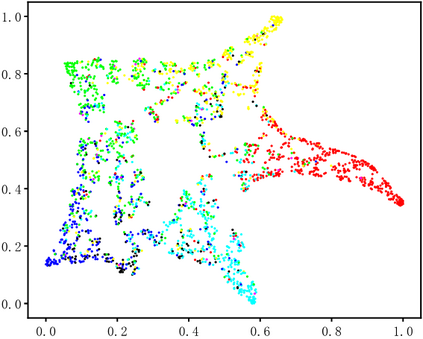
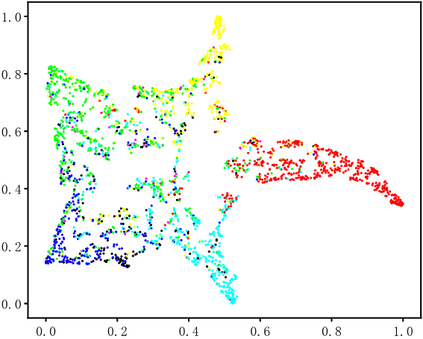
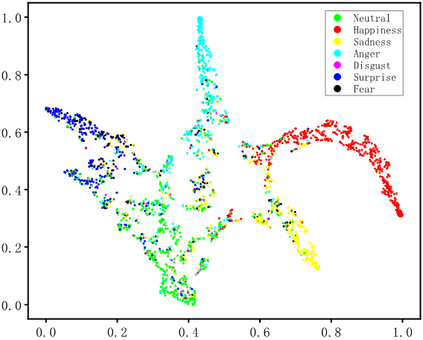
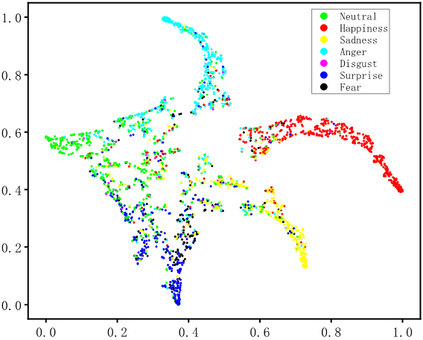
Dynamic facial expression recognition (DFER) in the wild is an extremely challenging task, due to a large number of noisy frames in the video sequences. Previous works focus on extracting more discriminative features, but ignore distinguishing the key frames from the noisy frames. To tackle this problem, we propose a noise-robust dynamic facial expression recognition network (NR-DFERNet), which can effectively reduce the interference of noisy frames on the DFER task. Specifically, at the spatial stage, we devise a dynamic-static fusion module (DSF) that introduces dynamic features to static features for learning more discriminative spatial features. To suppress the impact of target irrelevant frames, we introduce a novel dynamic class token (DCT) for the transformer at the temporal stage. Moreover, we design a snippet-based filter (SF) at the decision stage to reduce the effect of too many neutral frames on non-neutral sequence classification. Extensive experimental results demonstrate that our NR-DFERNet outperforms the state-of-the-art methods on both the DFEW and AFEW benchmarks.
翻译:野生的动态面部识别( DFER) 是一项极具挑战性的任务, 因为在视频序列中有大量的噪音框。 先前的工作重点是提取更具歧视性的特征, 但却忽略了从噪音框中区分关键框架。 为了解决这个问题, 我们提议建立一个噪音- 机器人动态面部识别网络( NR- DFERNet ), 以有效减少噪音框对 DFER 任务的干扰。 具体地说, 在空间阶段, 我们设计了一个动态- 静态聚合模块( DSF ), 将动态特征引入静态特征, 以学习更具歧视性的空间特征。 为了抑制目标不相干框架的影响, 我们在时间阶段为变异器引入了新型的动态类符号( DDCT ) 。 此外, 我们设计了一个在决策阶段的基于片段的过滤器( SFFF), 以减少过多中性框架对非中性序列分类的影响。 广泛的实验结果表明, 我们的NR- DFERNet 超越了 DFEW 和 AFEW 基准中的最新方法。