
1. 引言
人脸表情识别旨在通过对面部行为的识别从而分析目标对象的情感状态,具体的任务是将一张人脸图片或者一段面部视频分类为七类基本情感之一,即,中性、高兴、悲伤、伤心、惊讶、害怕、厌恶、以及生气。由于面部表情本质上是面部动作变化,而其本身就是动态的,因此基于视频序列的面部动作变化可以更好地描述表情。相对于实验室场景下的动态表情识别,自然场景存在着遮挡、非正脸、和头部运动等问题,但更具有研究价值。基于此,本文提出了基于Transformer的识别网络用于自然场景下的动态人脸表情识别。
2. 基于Transformer的动态人脸表情识别网络
最近,研究表明Transformer网络具有强大的特征表达能力,在很多计算机视觉任务上表现出了非常好的性能。而对于动态人脸表情识别任务,从空间角度来看,人脸整体图像中分割出来的人脸局部块可以看作是视觉“单词”序列,从时间角度来看,面部视频片段是连续的,视频片段的每一帧也可以看作是一个视觉“单词”。此外,Transformer中的自注意力机制可以学习每一帧人脸局部特征之间的相关性和人脸视频序列之间的相关性,而这种相关性的学习能够很好地缓解自然场景下遮挡、非正脸、和头部运动等问题的影响。具体的网络结构如图1所示。
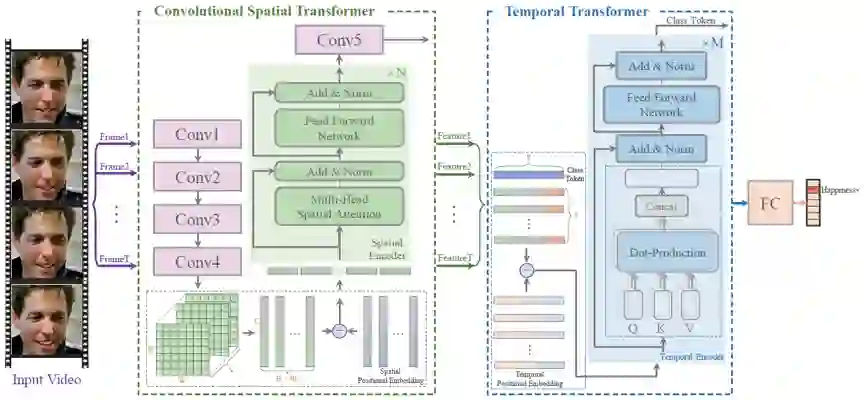
3. 实验
为了检验Former-DFER对于动态人脸表情识别的有效性,我们在两个视频表情识别数据集上做了实验,表1和表2分别展示了Former-DFER在DFER和AFEW上的性能表现。
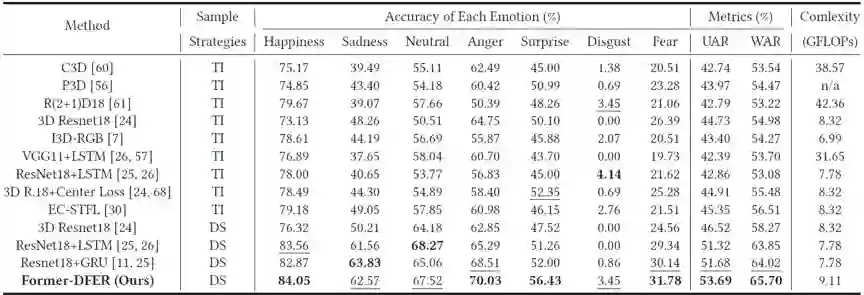
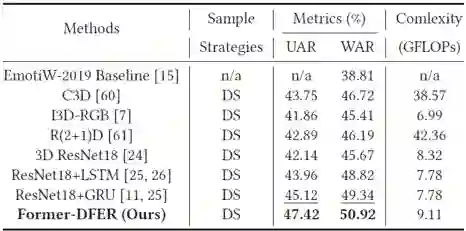
综合来看,相比以往动态人脸表情识别中的常用方法以及SOTA方法,Former-DFER在两个数据集上均带来了较大性能提升。
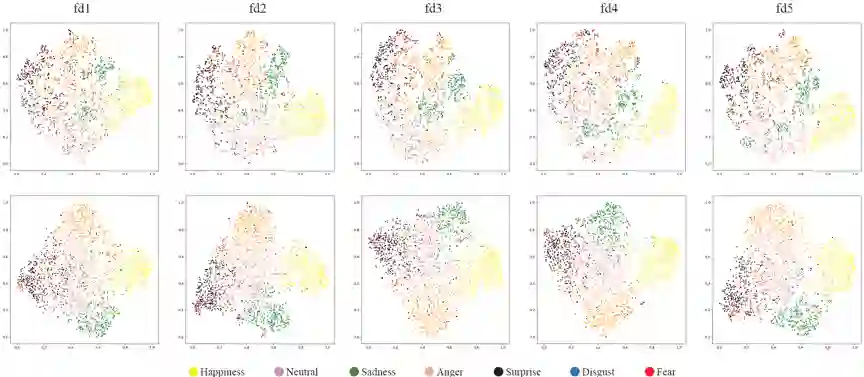
4. 可视化
作者:赵增群, 刘青山
单位:南京信息工程大学
邮箱:
论文:
https://dl.acm.org/doi/10.1145/3474085.3475292
代码:


