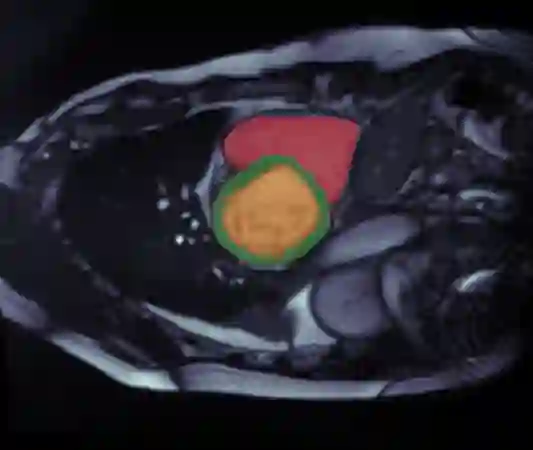
Supervised machine learning provides state-of-the-art solutions to a wide range of computer vision problems. However, the need for copious labelled training data limits the capabilities of these algorithms in scenarios where such input is scarce or expensive. Self-supervised learning offers a way to lower the need for manually annotated data by pretraining models for a specific domain on unlabelled data. In this approach, labelled data are solely required to fine-tune models for downstream tasks. Medical image segmentation is a field where labelling data requires expert knowledge and collecting large labelled datasets is challenging; therefore, self-supervised learning algorithms promise substantial improvements in this field. Despite this, self-supervised learning algorithms are used rarely to pretrain medical image segmentation networks. In this paper, we elaborate and analyse the effectiveness of supervised and self-supervised pretraining approaches on downstream medical image segmentation, focusing on convergence and data efficiency. We find that self-supervised pretraining on natural images and target-domain-specific images leads to the fastest and most stable downstream convergence. In our experiments on the ACDC cardiac segmentation dataset, this pretraining approach achieves 4-5 times faster fine-tuning convergence compared to an ImageNet pretrained model. We also show that this approach requires less than five epochs of pretraining on domain-specific data to achieve such improvement in the downstream convergence time. Finally, we find that, in low-data scenarios, supervised ImageNet pretraining achieves the best accuracy, requiring less than 100 annotated samples to realise close to minimal error.
翻译:受监督的机器学习为一系列广泛的计算机视觉问题提供了最先进的解决方案。然而,由于需要大量贴上标签的培训数据,在这种投入稀缺或昂贵的情况下,这些算法的能力受到限制。自我监督的学习为降低人工附加附加说明数据的需求提供了一种途径,即通过未贴标签数据特定域的预培训模型来降低人工附加附加附加说明数据的需求。在这一方法中,只有贴上标签的数据才能对下游任务模型进行微调。医学图像分割是一个贴标签数据需要专家知识并收集大量标签的网络数据集具有挑战性的领域;因此,自我监督的学习算法有望大大改进该领域的准确性。尽管如此,自我监督的学习算法很少用于预先培养医学图像分割网络网络。在本文中,我们详细阐述并分析下游医学图象分类的监管和自我监督前培训方法的有效性,侧重于趋同和数据效率。我们发现,在自然图像和特定目标域域图象的自我监督前培训中,最慢和最不稳定的预变近于下游趋同。我们在ACDC心脏病分类方法上进行精细的实验中,我们还需要进行最慢的升级前的数据转换。