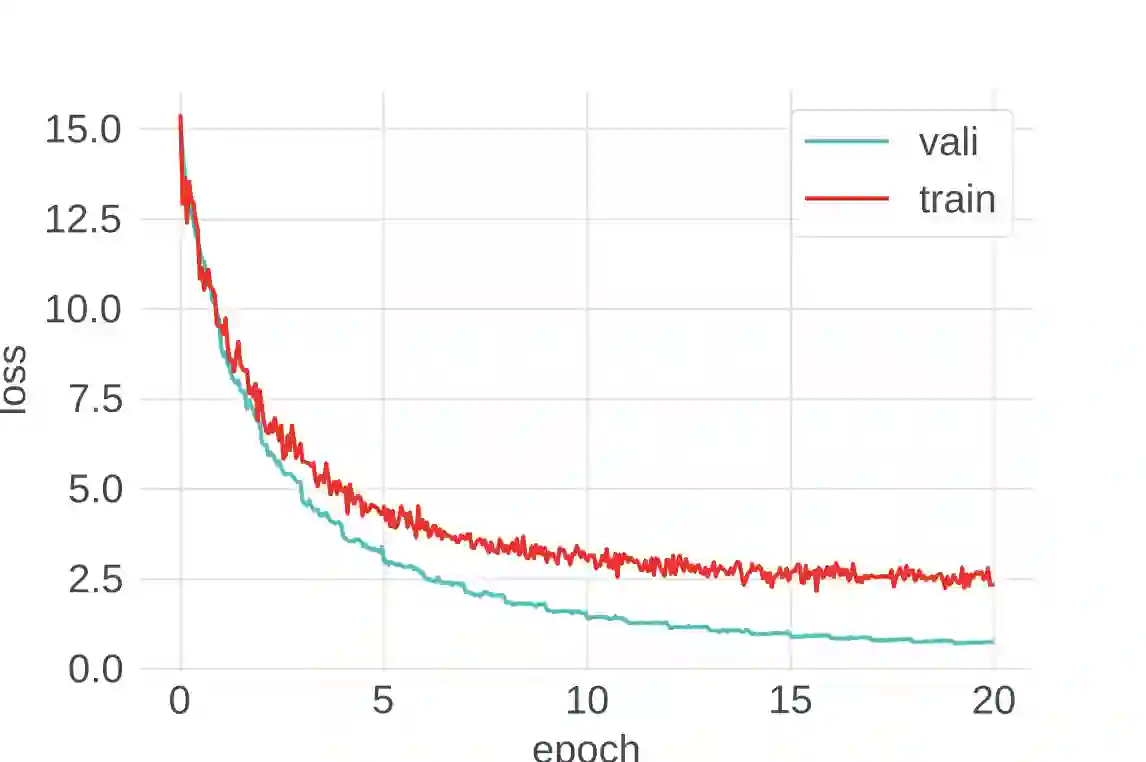
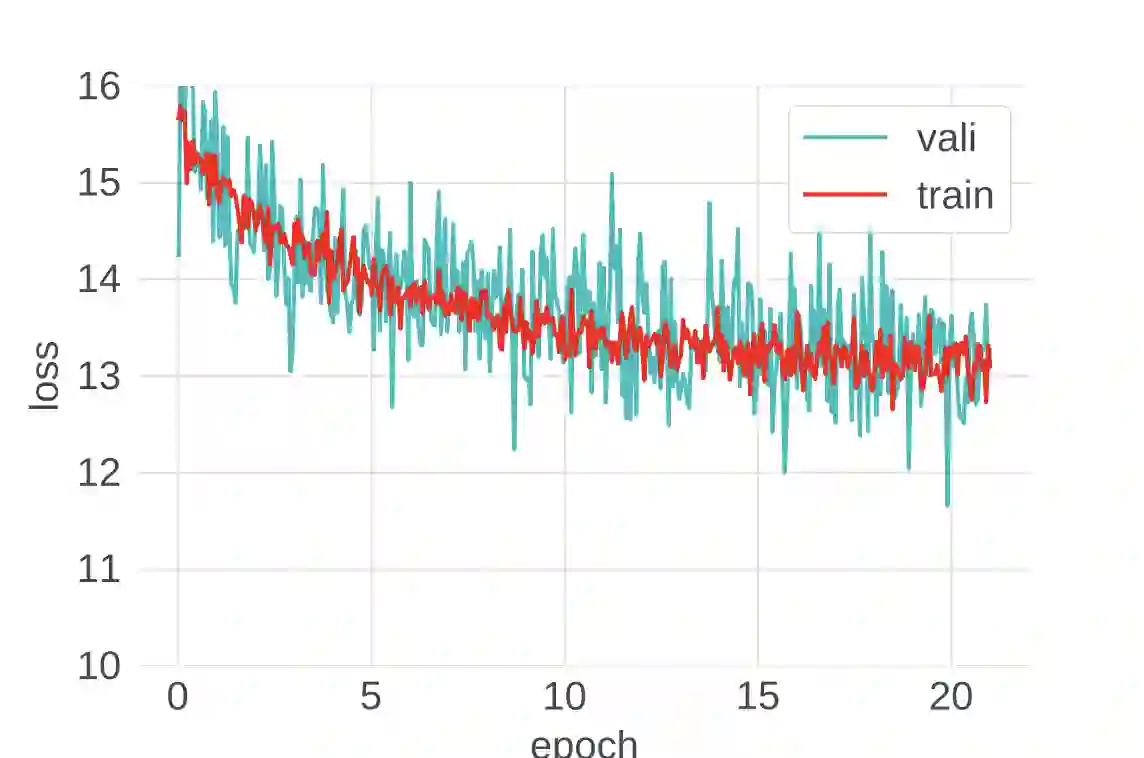
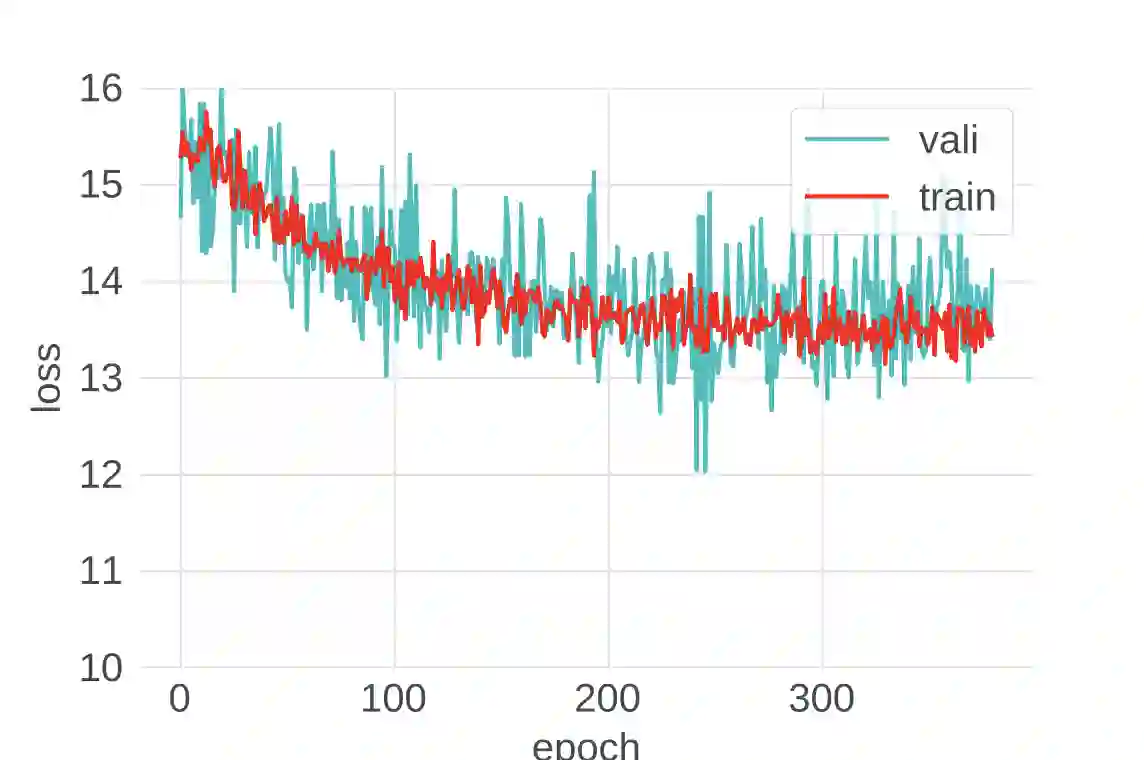
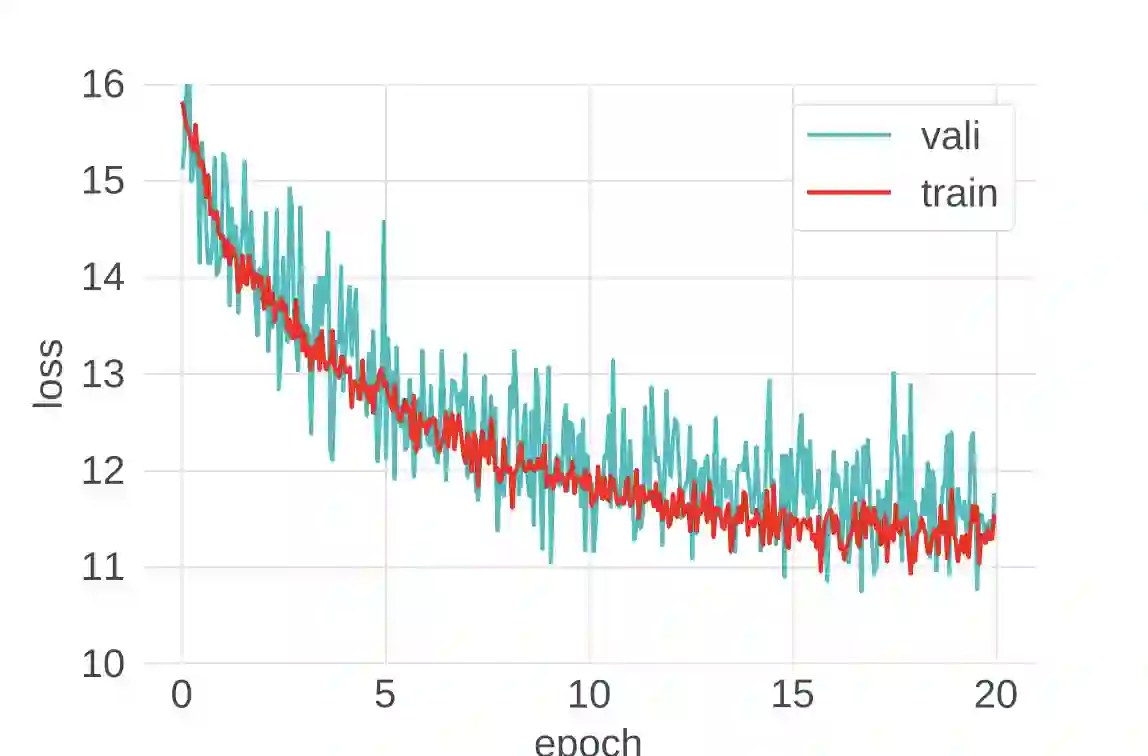
Despite intense interest and considerable effort, the current generation of neural networks suffers a significant loss of accuracy under most practically relevant privacy training regimes. One particularly challenging class of neural networks are the wide ones, such as those deployed for NLP typeahead prediction or recommender systems. Observing that these models share something in common--an embedding layer that reduces the dimensionality of the input--we focus on developing a general approach towards training these models that takes advantage of the sparsity of the gradients. More abstractly, we address the problem of differentially private empirical risk minimization (ERM) for models that admit sparse gradients. We demonstrate that for non-convex ERM problems, the loss is logarithmically dependent on the number of parameters, in contrast with polynomial dependence for the general case. Following the same intuition, we propose a novel algorithm for privately training neural networks. Finally, we provide an empirical study of a DP wide neural network on a real-world dataset, which has been rarely explored in the previous work.
翻译:尽管人们对此兴趣极大,而且付出了相当大的努力,但目前一代神经网络在大多数实际相关的隐私培训制度下却大大丧失了准确性。一个特别具有挑战性的神经网络类别是广阔的神经网络,例如为NLP型头预测或建议系统部署的神经网络。注意到这些模型在共同嵌入层中具有某种共同特征,降低了投入-我们注重制定一种通用方法来培训这些模型,利用梯度的广度。更抽象地说,我们处理的是允许稀薄梯度模型的差别化私人经验风险最小化问题。我们证明,对于非软体机构风险管理问题,损失是在逻辑上取决于参数的数量,而对于一般案例则取决于多面性依赖性。根据同样的直觉,我们建议对私人培训神经网络采用新的算法。最后,我们用一个实际世界数据集对DP宽度的神经网络进行实证研究,而以前的工作很少对此加以探讨。