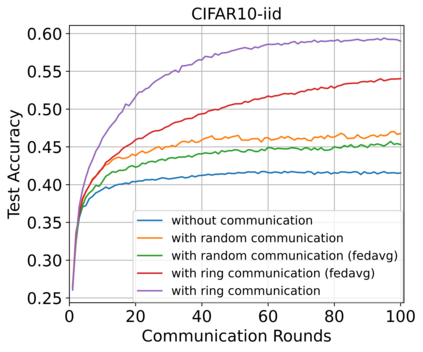
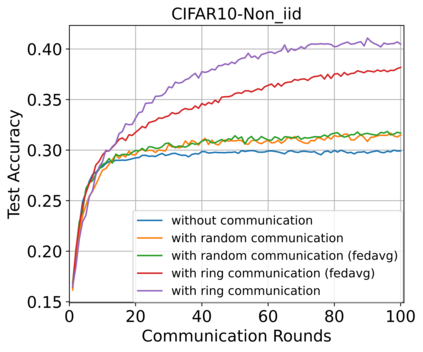
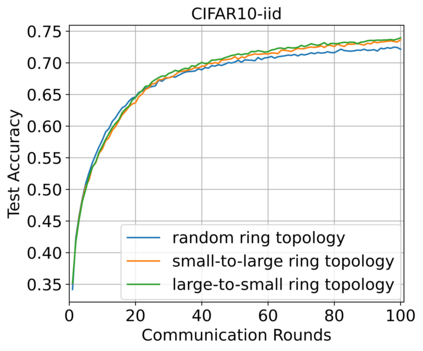
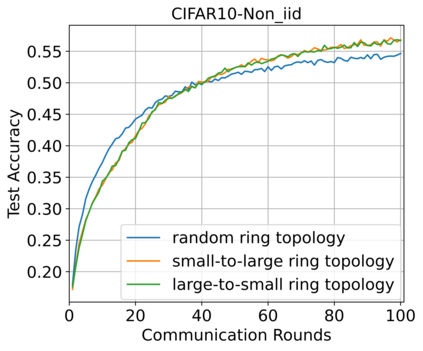
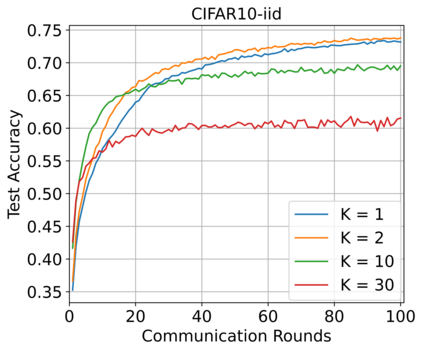
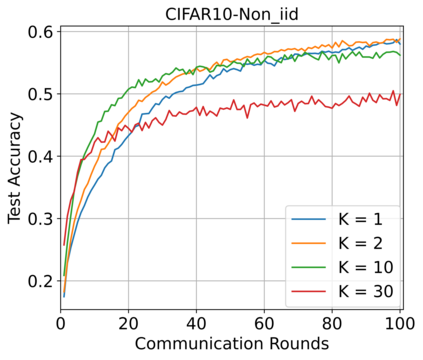
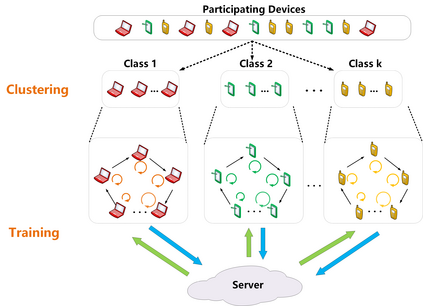
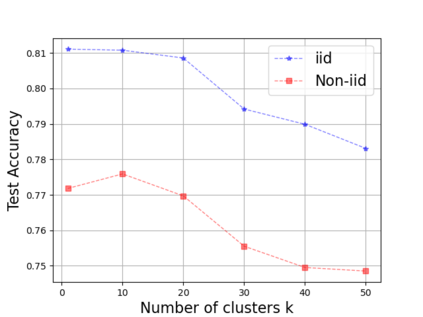
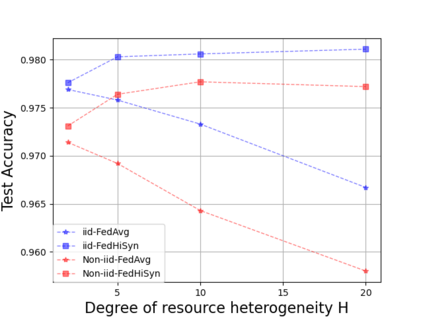
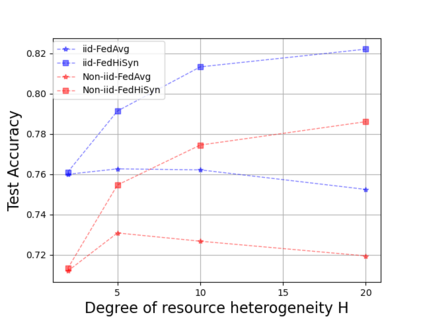
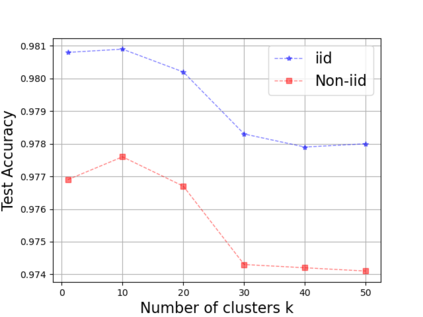
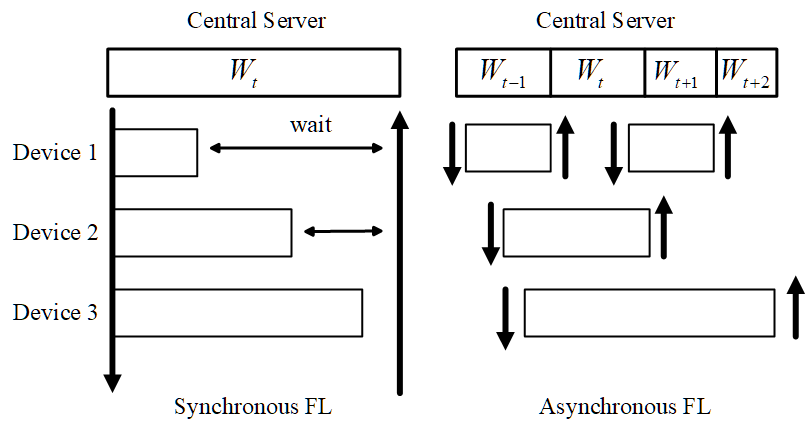
Federated Learning (FL) enables training a global model without sharing the decentralized raw data stored on multiple devices to protect data privacy. Due to the diverse capacity of the devices, FL frameworks struggle to tackle the problems of straggler effects and outdated models. In addition, the data heterogeneity incurs severe accuracy degradation of the global model in the FL training process. To address aforementioned issues, we propose a hierarchical synchronous FL framework, i.e., FedHiSyn. FedHiSyn first clusters all available devices into a small number of categories based on their computing capacity. After a certain interval of local training, the models trained in different categories are simultaneously uploaded to a central server. Within a single category, the devices communicate the local updated model weights to each other based on a ring topology. As the efficiency of training in the ring topology prefers devices with homogeneous resources, the classification based on the computing capacity mitigates the impact of straggler effects. Besides, the combination of the synchronous update of multiple categories and the device communication within a single category help address the data heterogeneity issue while achieving high accuracy. We evaluate the proposed framework based on MNIST, EMNIST, CIFAR10 and CIFAR100 datasets and diverse heterogeneous settings of devices. Experimental results show that FedHiSyn outperforms six baseline methods, e.g., FedAvg, SCAFFOLD, and FedAT, in terms of training accuracy and efficiency.
翻译:联邦学习联合会(FL)能够培训一个全球模型,但不分享在多个设备上储存的分散原始数据,以保护数据隐私。由于设备的能力各不相同,FL框架努力解决分层效应和过时模型的问题。此外,数据异质性使FL培训过程中的全球模型的准确性严重退化。为了解决上述问题,我们提议了一个等级同步FL框架,即FedhiSyn. FedhiSyn. FedhiSyn首先将所有可用的设备根据其计算能力分成少数类别。经过一段时间的当地培训,不同类别培训的模型同时上传到中央服务器。在一个类别内,这些装置根据环形表层学将当地更新的模型重量相互告知对方。由于环形学培训的效率更倾向于使用资源均匀的装置,基于计算能力的分类减轻了strigler效应的影响。此外,多个类别的同步更新以及设备通信在一个类别内帮助解决数据异质性问题,同时实现高精度的FARAT 6 IMFRA 标准,我们评估了基于FIRS IMFRA 和IMF IMFL 6 数据格式的拟议框架。