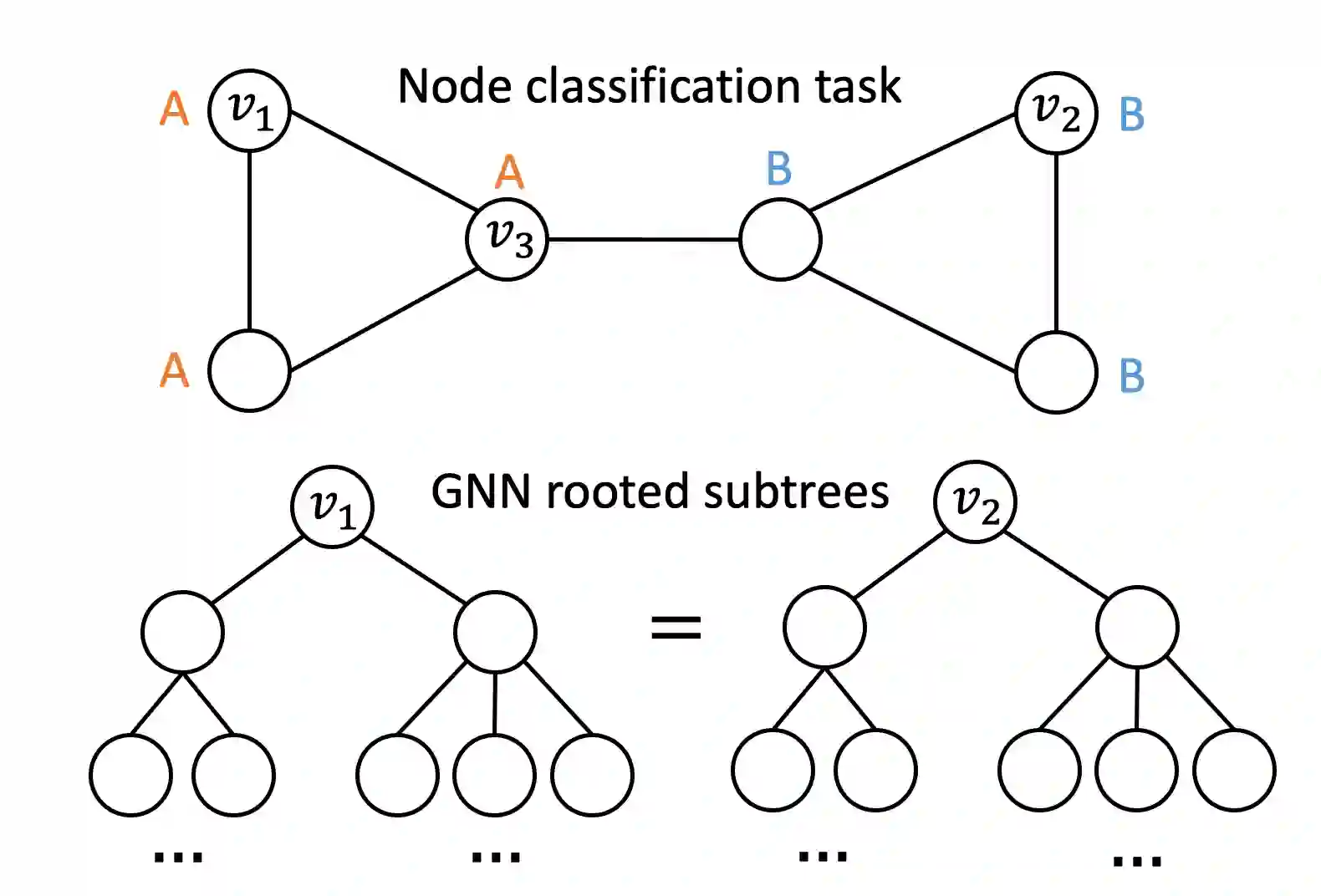
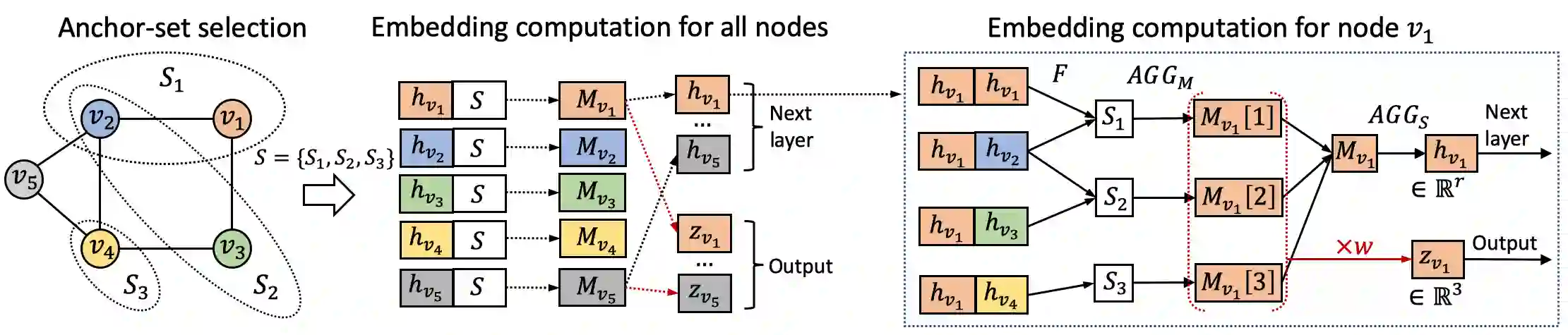
Learning node embeddings that capture a node's position within the broader graph structure is crucial for many prediction tasks on graphs. However, existing Graph Neural Network (GNN) architectures have limited power in capturing the position/location of a given node with respect to all other nodes of the graph. Here we propose Position-aware Graph Neural Networks (P-GNNs), a new class of GNNs for computing position-aware node embeddings. P-GNN first samples sets of anchor nodes, computes the distance of a given target node to each anchor-set,and then learns a non-linear distance-weighted aggregation scheme over the anchor-sets. This way P-GNNs can capture positions/locations of nodes with respect to the anchor nodes. P-GNNs have several advantages: they are inductive, scalable,and can incorporate node feature information. We apply P-GNNs to multiple prediction tasks including link prediction and community detection. We show that P-GNNs consistently outperform state of the art GNNs, with up to 66% improvement in terms of the ROC AUC score.
翻译:在更宽的图形结构中显示节点位置的学习嵌入节点对于许多图形上的预测任务至关重要。 然而, 现有的图形神经网络( GNN) 结构在图形所有其他节点上捕捉给定节点的位置/ 位置的权力有限。 我们在这里提议定位- 观测图形神经网络( P- GNN), 这是计算位置- 认知嵌入的一个新的GNN 类别。 P- GNN 首组锚节点样本, 计算给定目标节点与每个锁定点的距离, 然后在锁定点上学习非线性远程加权集合计划。 P- GNNN 能够捕捉到锚节点上的节点位置/ 位置/ 位置。 P- GNNN 有几个优点: 它们具有感性、 可缩放性, 并且可以包含节点特性信息。 我们将 P- GNNN 用于多个预测任务, 包括连接预测和社区探测 。 我们显示 P- GNNP 持续超越了 GNNC 和 RONC 升级 的 条件, 升级到 RONB% 。