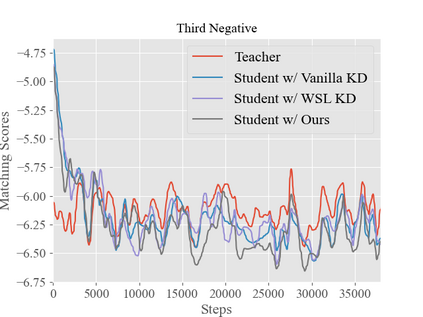
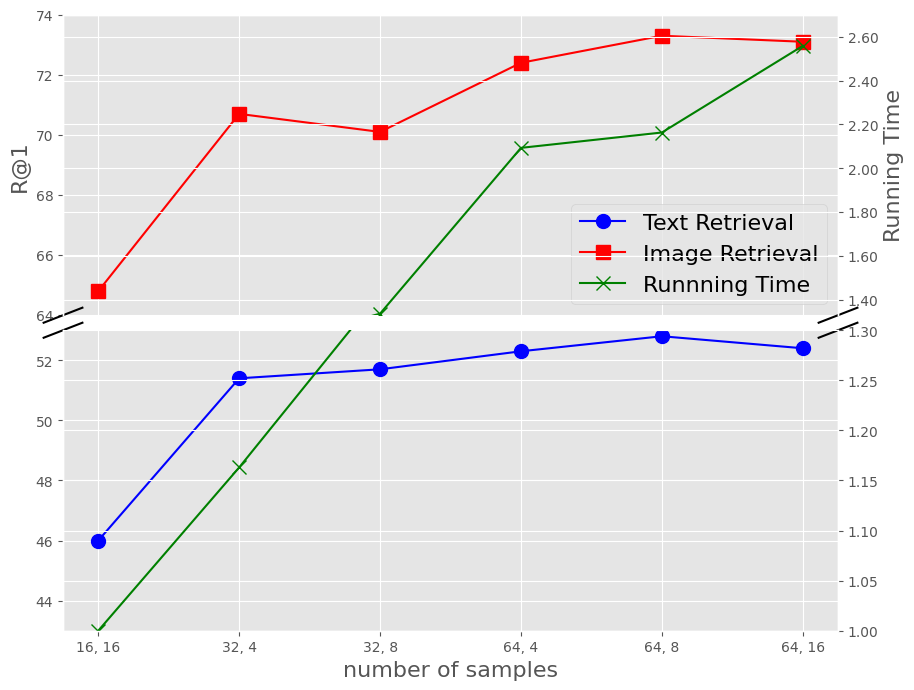
Although the vision-and-language pretraining (VLP) equipped cross-modal image-text retrieval (ITR) has achieved remarkable progress in the past two years, it suffers from a major drawback: the ever-increasing size of VLP models restricts its deployment to real-world search scenarios (where the high latency is unacceptable). To alleviate this problem, we present a novel plug-in dynamic contrastive distillation (DCD) framework to compress the large VLP models for the ITR task. Technically, we face the following two challenges: 1) the typical uni-modal metric learning approach is difficult to directly apply to the cross-modal tasks, due to the limited GPU memory to optimize too many negative samples during handling cross-modal fusion features. 2) it is inefficient to static optimize the student network from different hard samples, which have different effects on distillation learning and student network optimization. We try to overcome these challenges from two points. First, to achieve multi-modal contrastive learning, and balance the training costs and effects, we propose to use a teacher network to estimate the difficult samples for students, making the students absorb the powerful knowledge from pre-trained teachers, and master the knowledge from hard samples. Second, to dynamic learn from hard sample pairs, we propose dynamic distillation to dynamically learn samples of different difficulties, from the perspective of better balancing the difficulty of knowledge and students' self-learning ability. We successfully apply our proposed DCD strategy to two state-of-the-art vision-language pretrained models, i.e. ViLT and METER. Extensive experiments on MS-COCO and Flickr30K benchmarks show the effectiveness and efficiency of our DCD framework. Encouragingly, we can speed up the inference at least 129$\times$ compared to the existing ITR models.
翻译:虽然视觉和语言预演(VLP)设备齐全的跨模式图像-文字检索(ITR)在过去两年中取得了显著进展,但还是有一大缺陷:VLP模型的尺寸越来越小,限制了其部署到现实世界搜索场(高悬浮令人无法接受 ) 。为了缓解这一问题,我们提出了一个新的插插插式动态对比蒸馏(DCD)框架,以压缩大型VLP模型来完成IMTR任务。技术上,我们面临着以下两个挑战:1)典型的单式标准学习方法很难直接适用于跨模式的实验任务:由于GPU记忆有限,在处理交叉模式融合功能时只能优化过多的负面样本。2 静态地优化来自不同硬样本的学生网络是低效的,对蒸馏学习和学生网络优化有不同的影响。首先,我们要实现多式对比学习,平衡培训成本和效果,我们提议使用教师网络来对二类动态模型进行更平衡,从动态模型中学习硬的样本。