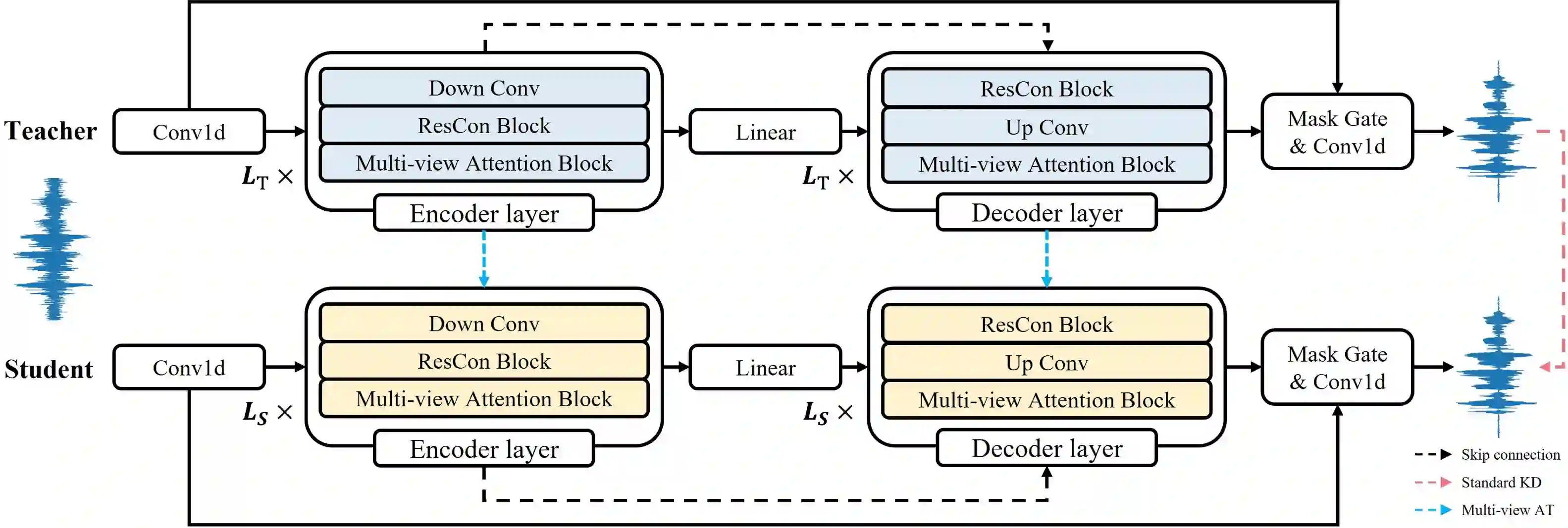
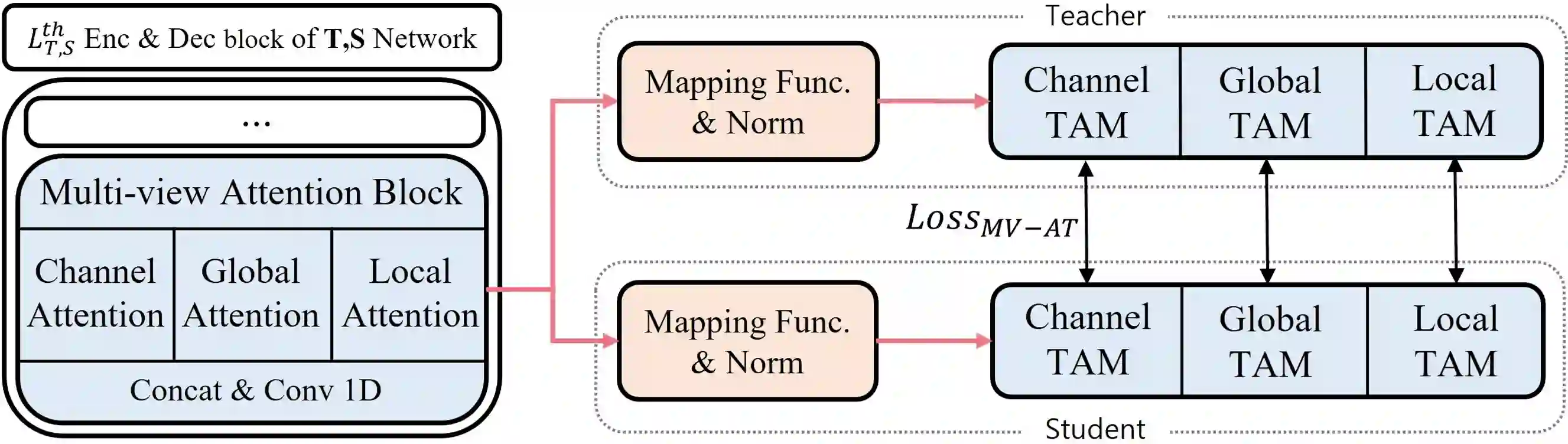
Recent deep learning models have achieved high performance in speech enhancement; however, it is still challenging to obtain a fast and low-complexity model without significant performance degradation. Previous knowledge distillation studies on speech enhancement could not solve this problem because their output distillation methods do not fit the speech enhancement task in some aspects. In this study, we propose multi-view attention transfer (MV-AT), a feature-based distillation, to obtain efficient speech enhancement models in the time domain. Based on the multi-view features extraction model, MV-AT transfers multi-view knowledge of the teacher network to the student network without additional parameters. The experimental results show that the proposed method consistently improved the performance of student models of various sizes on the Valentini and deep noise suppression (DNS) datasets. MANNER-S-8.1GF with our proposed method, a lightweight model for efficient deployment, achieved 15.4x and 4.71x fewer parameters and floating-point operations (FLOPs), respectively, compared to the baseline model with similar performance.
翻译:最近深层次的学习模式在增强语言能力方面取得了很高的成绩;然而,在不出现显著的性能退化的情况下,获得快速和低复杂性模式仍是一项挑战; 以往关于增强语言能力的知识蒸馏研究无法解决这个问题,因为其产出蒸馏方法在某些方面不符合增强语言能力的任务; 在本研究中,我们提议采用多视调调换(MV-AT),即基于地貌的蒸馏,以便在时间范围内获得有效的增强语言能力模式; 根据多视特征提取模型,MV-AT将教师网络的多视知识传输到学生网络,而不增加参数; 实验结果显示,拟议的方法一贯地改进了瓦伦蒂和深噪音抑制(DNS)数据集不同尺寸学生模型的性能。 MANNER-S-8.1GF与我们拟议的方法,即高效部署的轻量模型,分别实现了15.4x和4.71x参数和浮点操作(FLOPs),与类似性能的基线模型相比,分别减少了15.4x和4.71x参数和浮点操作(FLOPs)。