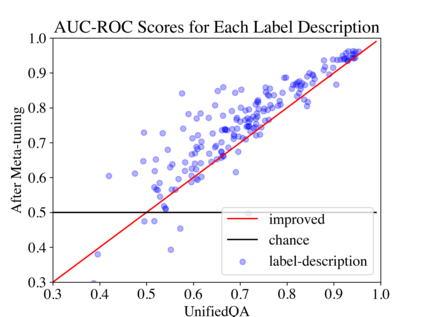
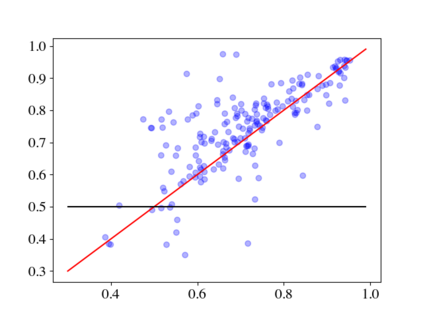
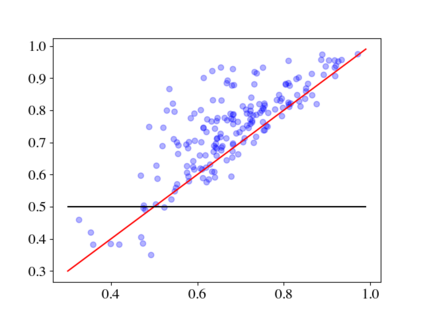
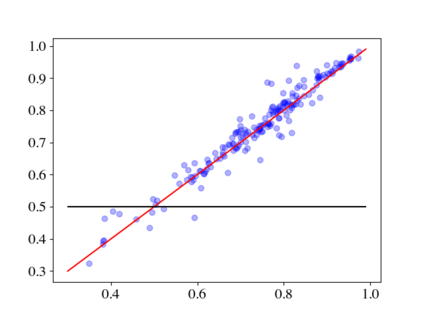
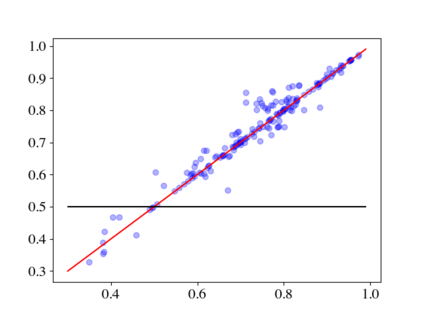
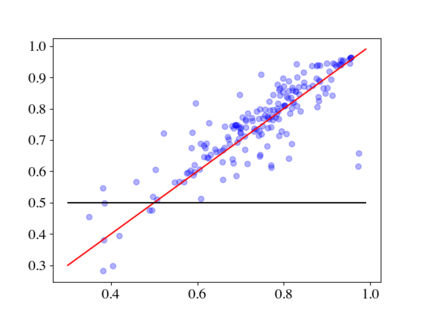
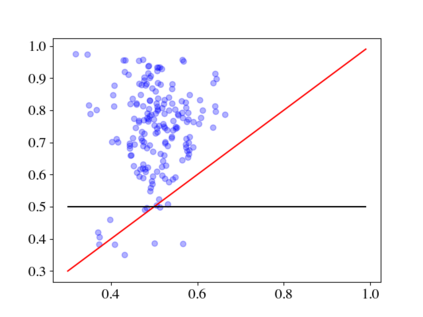
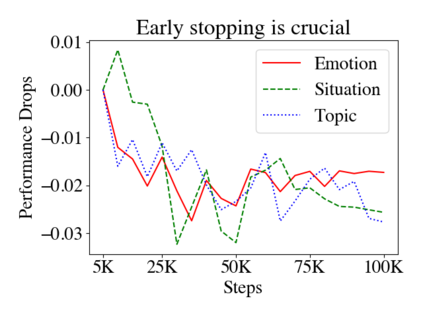
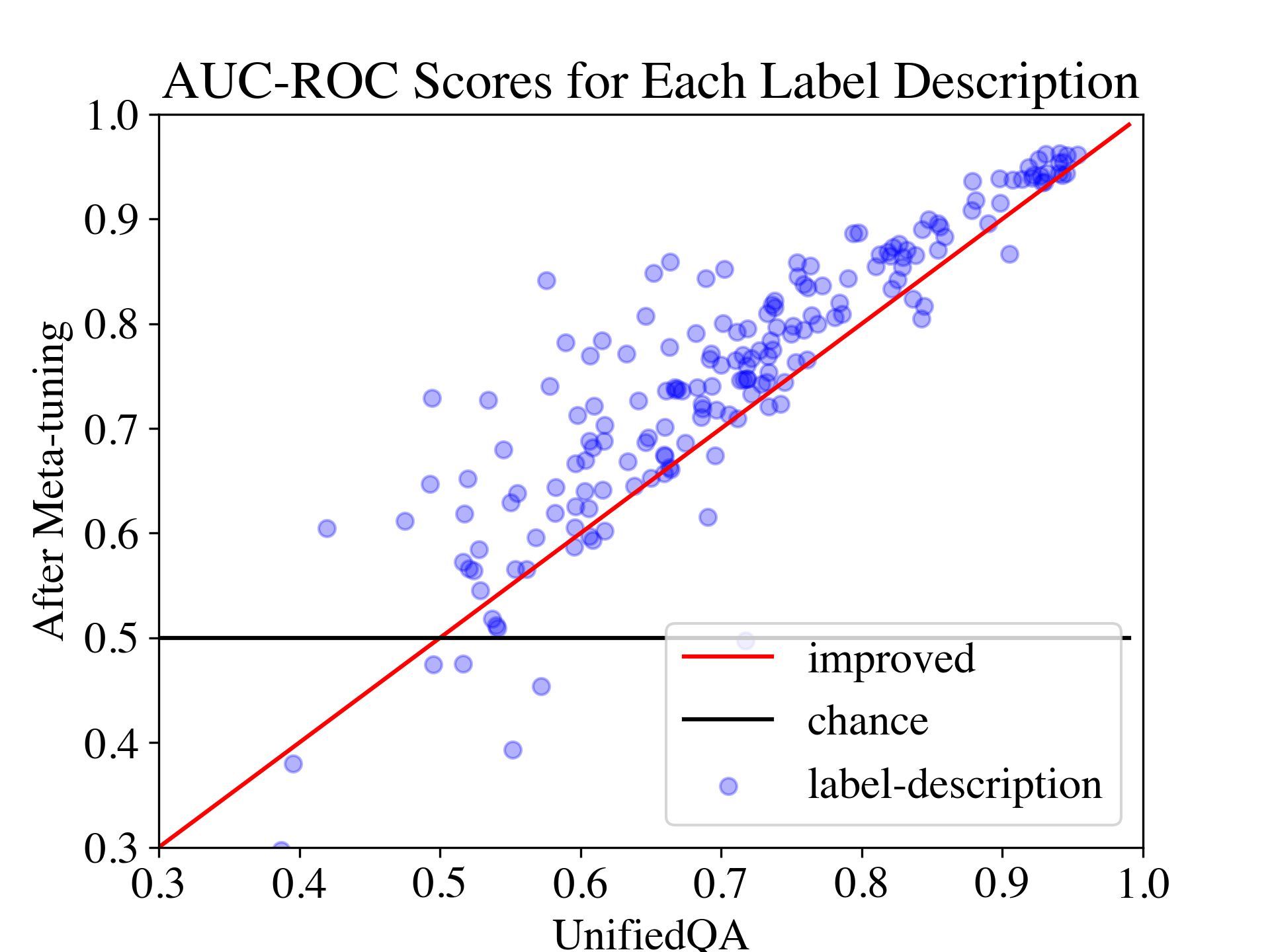
Large pre-trained language models (LMs) such as GPT-3 have acquired a surprising ability to perform zero-shot learning. For example, to classify sentiment without any training examples, we can "prompt" the LM with the review and the label description "Does the user like this movie?", and ask whether the next word is "yes" or "no". However, the next word prediction training objective is still misaligned with the target zero-shot learning objective. To address this weakness, we propose meta-tuning, which directly optimizes the zero-shot learning objective by fine-tuning pre-trained language models on a collection of datasets. We focus on classification tasks, and construct the meta-dataset by aggregating 43 existing datasets and annotating 441 label descriptions in a question-answering (QA) format. When evaluated on unseen tasks, meta-tuned models outperform a same-sized QA model and the previous SOTA zero-shot learning system based on natural language inference. Additionally, increasing parameter count from 220M to 770M improves AUC-ROC scores by 6.3%, and we forecast that even larger models would perform better. Therefore, measuring zero-shot learning performance on language models out-of-the-box might underestimate their true potential, and community-wide efforts on aggregating datasets and unifying their formats can help build models that answer prompts better.
翻译:GPT-3 等大型预先培训语言模型(LMS) 已经获得了一个令人惊讶的零点学习能力。 例如, 将情绪分类而不做任何培训范例, 我们可以通过“ 快速” LM 进行“ 快速” LM 的审查和标签描述“ 用户喜欢这部电影”, 并询问下一个词是“ 是” 还是“ 不 ” 。 但是, 下一个字预测培训目标仍然与目标零点学习目标不相符。 为了解决这一弱点, 我们提议元调整, 通过对数据集收集的预培训语言模型进行微调, 直接优化零点学习目标。 我们专注于分类任务, 通过汇总43个现有数据集和在问答(QA)格式中说明441个标签描述, 来“ 快速” 来构建元数据集。 在对不可见的任务进行评估时, 元调整模型的大小比目标的QA模型和以前以自然语言为基础的SOTA零点学习系统要快。 此外, 将参数计数从220M 到 770M 改进 AUC-ROC 的评分分 6.3%, 我们专注于分类任务, 通过汇总43 和预测更精确的模型, 甚至可以更好地测量其潜在的精确的模型。