零样本文本分类,Zero-Shot Learning for Text Classification
最近发布的GPT-3让我对NLP中的零学习和小样本的状态产生了兴趣。虽然大多数的零样本学习研究集中在计算机视觉,也有一些有趣的工作在NLP领域。
我将会写一系列的博文来涵盖现有的关于NLP零样本学习的研究。在这第一篇文章中,我将解释Pushp等人的论文“一次训练,到处测试:文本分类的零样本学习”。本文从2017年12月开始,首次提出了文本分类的零样本学习范式。
什么是零样本学习?
零样本学习是检测模型在训练中从未见过的类的能力。它类似于我们人类在没有明确监督的情况下归纳和识别新事物的能力。
例如,我们想要做情感分类和新闻分类。通常,我们将为每个数据集训练/微调一个新模型。相比之下,零样本学习,你可以直接执行任务,如情绪和新闻分类,没有任何特定的任务训练。
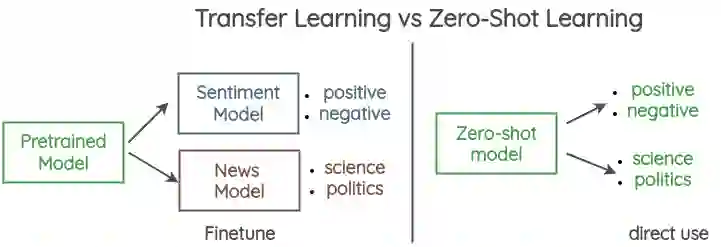
一次训练,随处测试
本文提出了一种简单的零样本分类方法。他们没有将文本分类为X类,而是将任务重新组织为二元分类,以确定文本和类是否相关。

https://amitness.com/2020/05/zero-shot-text-classification/
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“ZSLT” 可以获取《零样本文本分类》专知下载链接索引



登录查看更多
相关内容




相关VIP内容
相关资讯