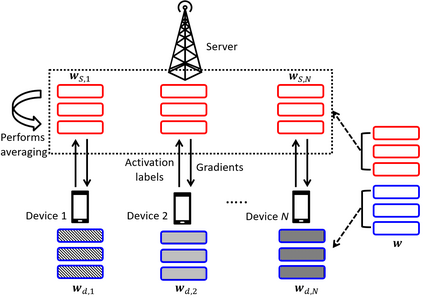
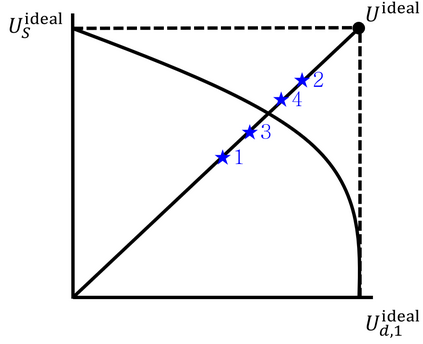
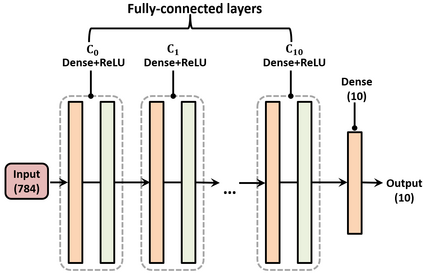
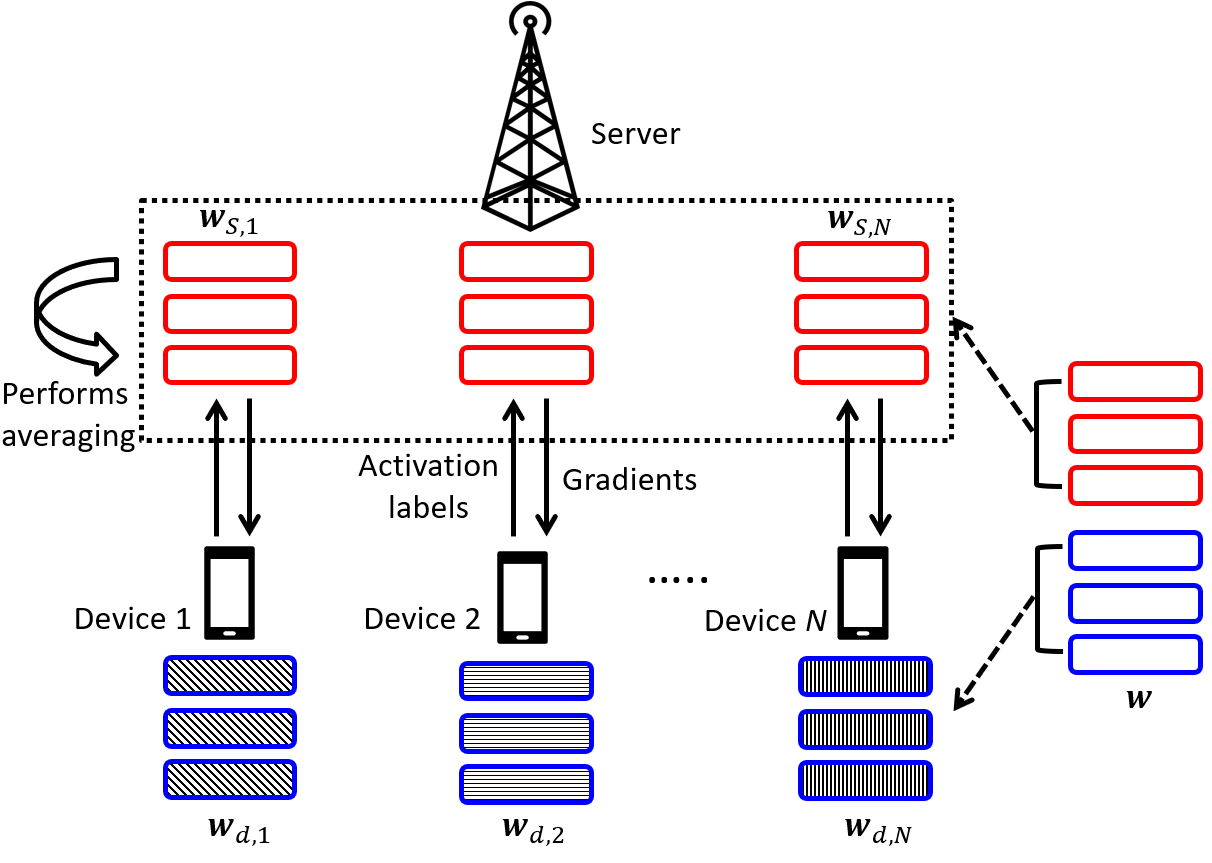
Split learning (SL) is an emergent distributed learning framework which can mitigate the computation and wireless communication overhead of federated learning. It splits a machine learning model into a device-side model and a server-side model at a cut layer. Devices only train their allocated model and transmit the activations of the cut layer to the server. However, SL can lead to data leakage as the server can reconstruct the input data using the correlation between the input and intermediate activations. Although allocating more layers to a device-side model can reduce the possibility of data leakage, this will lead to more energy consumption for resource-constrained devices and more training time for the server. Moreover, non-iid datasets across devices will reduce the convergence rate leading to increased training time. In this paper, a new personalized SL framework is proposed. For this framework, a novel approach for choosing the cut layer that can optimize the tradeoff between the energy consumption for computation and wireless transmission, training time, and data privacy is developed. In the considered framework, each device personalizes its device-side model to mitigate non-iid datasets while sharing the same server-side model for generalization. To balance the energy consumption for computation and wireless transmission, training time, and data privacy, a multiplayer bargaining problem is formulated to find the optimal cut layer between devices and the server. To solve the problem, the Kalai-Smorodinsky bargaining solution (KSBS) is obtained using the bisection method with the feasibility test. Simulation results show that the proposed personalized SL framework with the cut layer from the KSBS can achieve the optimal sum utilities by balancing the energy consumption, training time, and data privacy, and it is also robust to non-iid datasets.
翻译:分割式学习( SL) 是一个突发分布式的学习框架, 它可以减少计算和无线通信费, 从而降低联邦学习的计算和无线通信费。 它将机器学习模型分成一个设备边模型, 并在剪切层将服务器边模型分割成一个服务器边模型。 设备只培训分配的模型, 并将剪切层的启动器传送到服务器。 然而, SL 可能导致数据泄漏, 因为服务器可以使用输入和中间激活之间的关联来重建输入数据。 虽然将更多的层分配到设备边模型可以减少数据泄漏的可能性, 但这将导致资源限制装置的能源消耗消耗消耗量增加, 以及服务器的更多培训时间。 此外, 跨设备的非二位数据集将降低合并率, 导致培训时间增加。 在本文中, 新的个性化 SLL框架可以导致数据泄漏。 对于这个框架, 选择切割层, 可以优化计算和无线传输的能源消耗量之间的交换, 培训时间和数据隐私。 在考虑框架中, 每个设备边的模型可以减少非二位化的能源边模型可以减少非二层数据设置,, 并且共享服务器的S 节流的S 节流的温度测试的S 和S 测试的S 测试 。