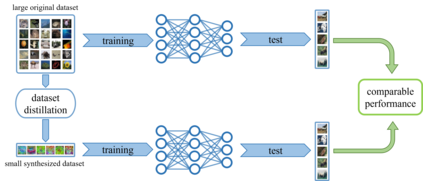
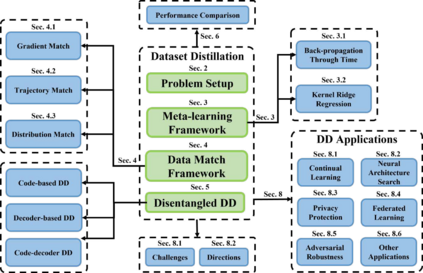
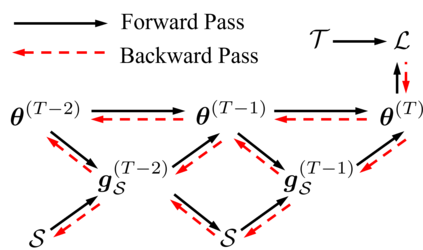
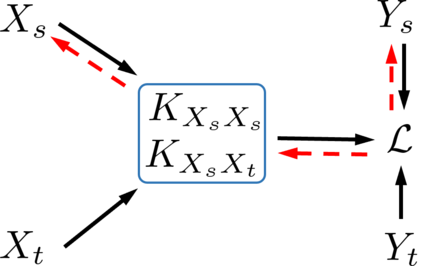
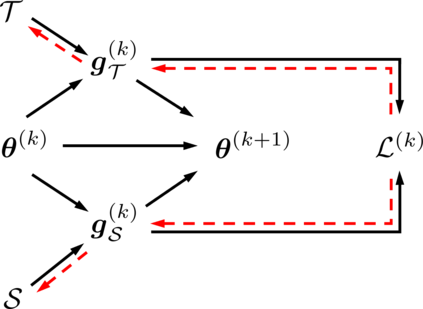
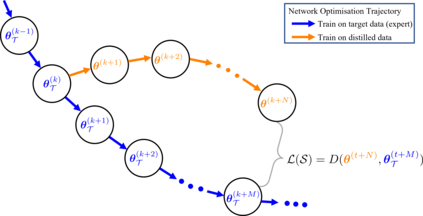
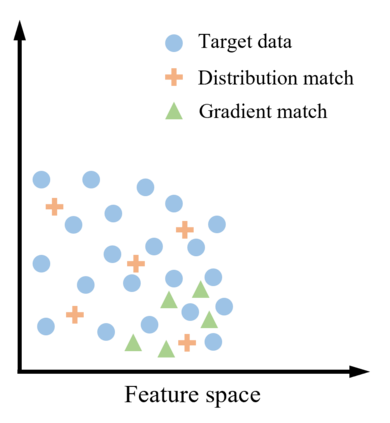
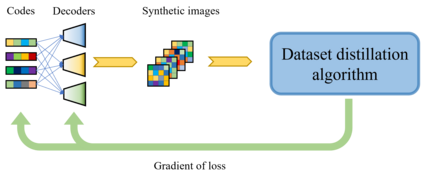
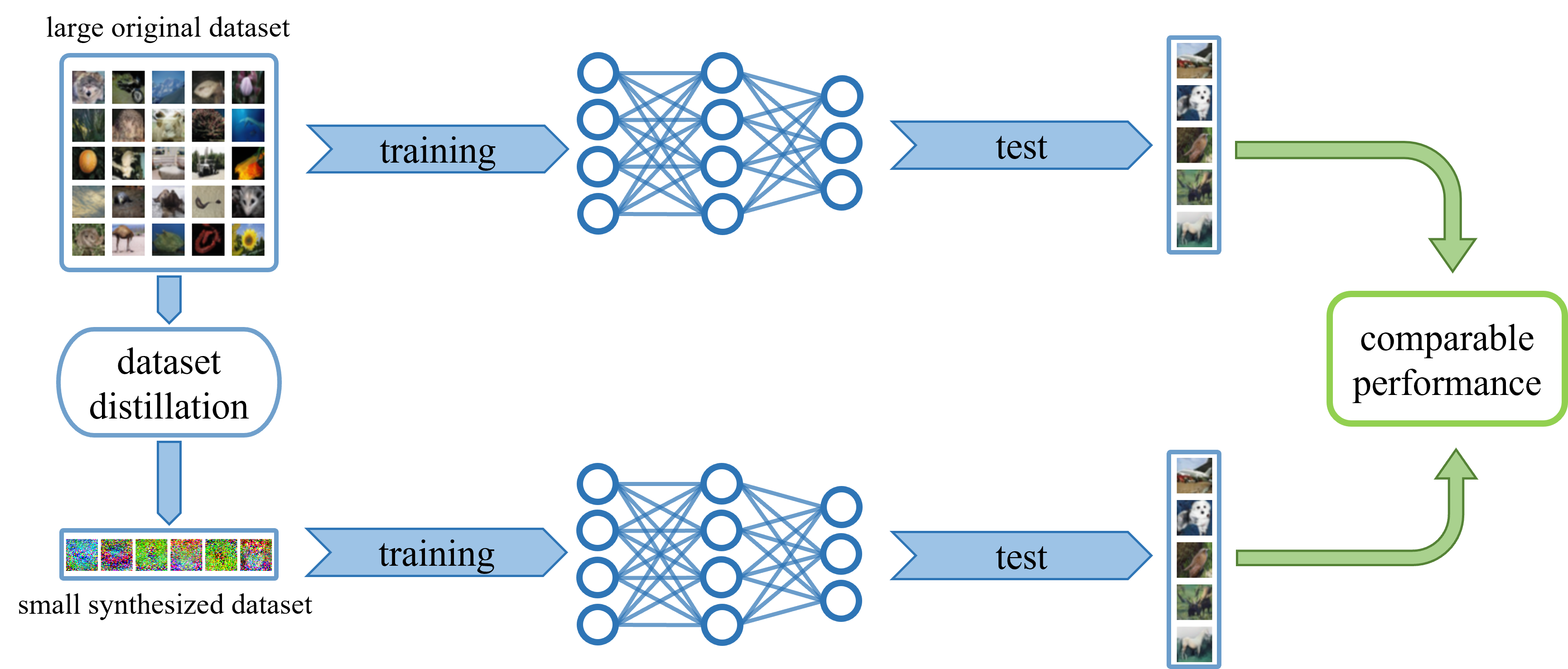
Deep learning technology has unprecedentedly developed in the last decade and has become the primary choice in many application domains. This progress is mainly attributed to a systematic collaboration that rapidly growing computing resources encourage advanced algorithms to deal with massive data. However, it gradually becomes challenging to cope with the unlimited growth of data with limited computing power. To this end, diverse approaches are proposed to improve data processing efficiency. Dataset distillation, one of the dataset reduction methods, tackles the problem via synthesising a small typical dataset from giant data and has attracted a lot of attention from the deep learning community. Existing dataset distillation methods can be taxonomised into meta-learning and data match framework according to whether explicitly mimic target data. Albeit dataset distillation has shown a surprising performance in compressing datasets, it still possesses several limitations such as distilling high-resolution data. This paper provides a holistic understanding of dataset distillation from multiple aspects, including distillation frameworks and algorithms, disentangled dataset distillation, performance comparison, and applications. Finally, we discuss challenges and promising directions to further promote future studies about dataset distillation.
翻译:过去十年来,深层学习技术史无前例地发展,成为许多应用领域的主要选择。这一进展主要归功于系统协作,快速增长的计算机资源鼓励先进的算法处理大量数据。然而,应对计算机功率有限的数据无限增长逐渐变得具有挑战性。为此,提出了提高数据处理效率的多种办法。作为减少数据的方法之一的数据集蒸馏方法之一,通过合成一个来自巨型数据的小型典型数据集来解决该问题,并吸引了深层学习界的极大关注。现有的数据集蒸馏方法可以分类成元学习和数据匹配框架,根据是否明确模拟目标数据进行分类。尽管数据集蒸馏显示在压缩数据集方面有惊人的性能,但仍有一些局限性,如蒸馏高分辨率数据等。本文提供了对数据元蒸馏的多个方面的全面理解,包括蒸馏框架和算法、分解的数据集蒸馏、性能比较和应用。最后,我们讨论了进一步推进未来关于数据蒸馏的研究的挑战和有希望的方向。