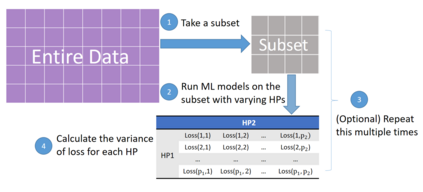
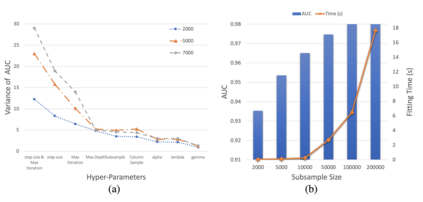
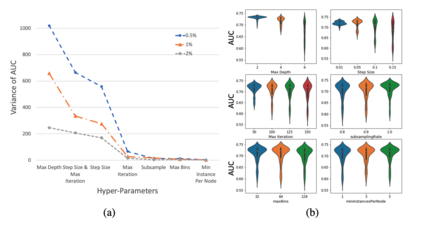
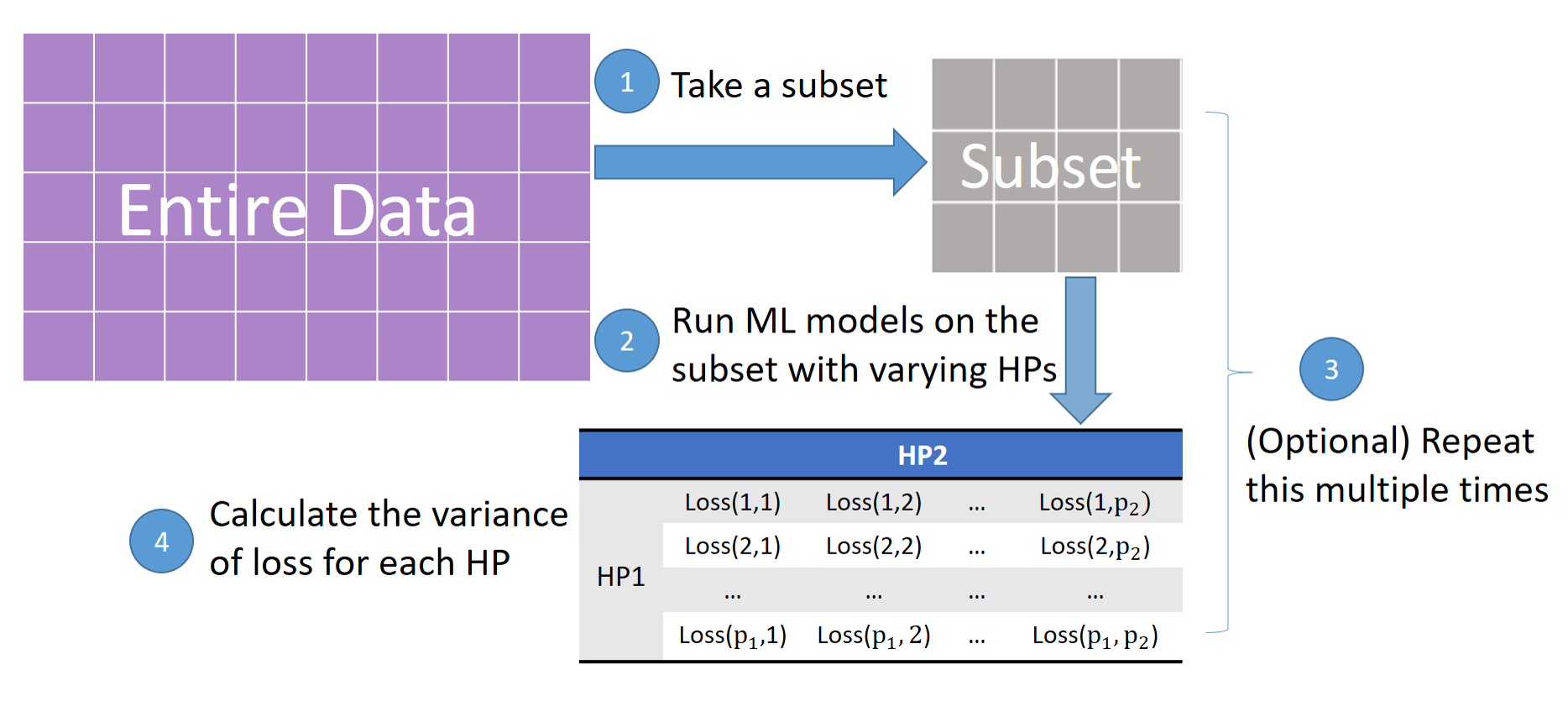
Hyperparameter plays an essential role in the fitting of supervised machine learning algorithms. However, it is computationally expensive to tune all the tunable hyperparameters simultaneously especially for large data sets. In this paper, we give a definition of hyperparameter importance that can be estimated by subsampling procedures. According to the importance, hyperparameters can then be tuned on the entire data set more efficiently. We show theoretically that the proposed importance on subsets of data is consistent with the one on the population data under weak conditions. Numerical experiments show that the proposed importance is consistent and can save a lot of computational resources.
翻译:超参数在设计受监督的机器学习算法方面起着关键作用。 但是,同时调整所有金枪鱼可捕量的超参数,特别是大型数据集的超参数,计算成本很高。 在本文中,我们给出了超参数重要性的定义,可以通过子取样程序来估计。根据重要性,超参数可以更有效率地调整整个数据集。我们从理论上表明,对数据子集的拟议重要性与在脆弱条件下人口数据的拟议重要性是一致的。数字实验表明,拟议的重要性是一致的,可以节省大量计算资源。