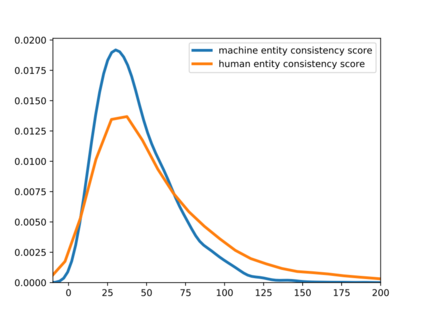
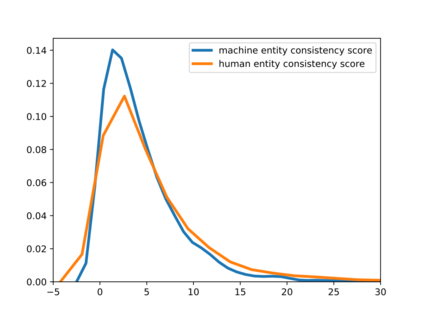
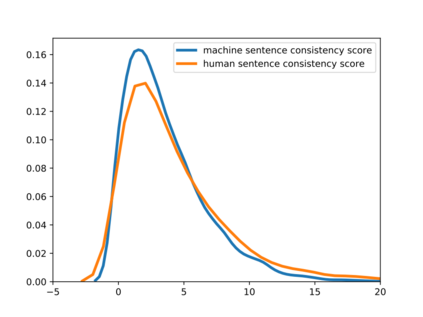
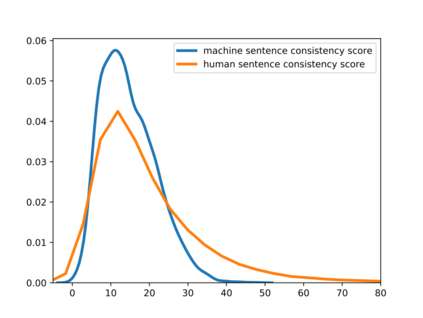
Deepfake detection, the task of automatically discriminating machine-generated text, is increasingly critical with recent advances in natural language generative models. Existing approaches to deepfake detection typically represent documents with coarse-grained representations. However, they struggle to capture factual structures of documents, which is a discriminative factor between machine-generated and human-written text according to our statistical analysis. To address this, we propose a graph-based model that utilizes the factual structure of a document for deepfake detection of text. Our approach represents the factual structure of a given document as an entity graph, which is further utilized to learn sentence representations with a graph neural network. Sentence representations are then composed to a document representation for making predictions, where consistent relations between neighboring sentences are sequentially modeled. Results of experiments on two public deepfake datasets show that our approach significantly improves strong base models built with RoBERTa. Model analysis further indicates that our model can distinguish the difference in the factual structure between machine-generated text and human-written text.
翻译:深假检测是自动歧视机器生成的文本的任务,随着自然语言基因化模型的最近进展,这种检测任务越来越重要。深假检测的现有方法通常代表粗糙的表示法文件。然而,它们努力捕捉文件的事实结构,而根据我们的统计分析,这是机器生成的文本和人写文本之间的一个歧视因素。为了解决这个问题,我们提出了一个基于图表的模型,利用文件的事实结构来深度检测文本。我们的方法代表了特定文件作为实体图的事实结构,进一步利用它来学习以图形神经网络表达的句号。然后,句式表述组成为作出预测的文件表示法,即相邻句子之间的一致关系是按顺序建模的。两个公共深假数据集的实验结果表明,我们的方法大大改进了与ROBERTA建立的强大基础模型。模型分析还表明,我们的模型可以区分机器生成的文本与人写文本之间在事实结构上的区别。