【论文推荐】最新八篇生成对抗网络相关论文—离散数据生成、设计灵感、语音波形合成、去模糊、视觉描述、语音转换、对齐方法、注意力
【导读】专知内容组整理了最近八篇生成对抗网络(Generative Adversarial Networks )相关文章,为大家进行介绍,欢迎查看!
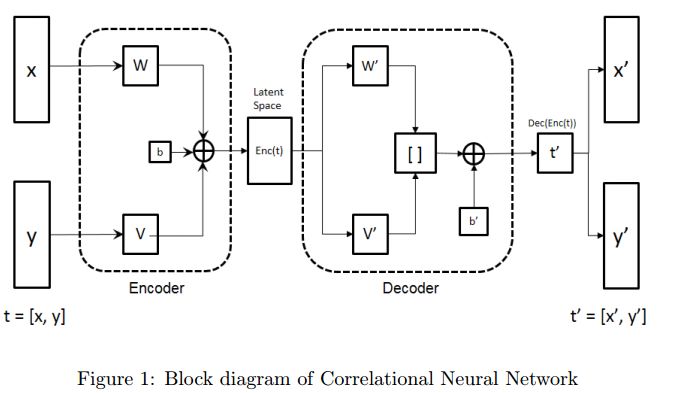
1.Correlated discrete data generation using adversarial training(使用对抗训练的相关离散数据生成)
作者:Shreyas Patel,Ashutosh Kakadiya,Maitrey Mehta,Raj Derasari,Rahul Patel,Ratnik Gandhi
机构:Ahmedabad University
摘要:Generative Adversarial Networks (GAN) have shown great promise in tasks like synthetic image generation, image inpainting, style transfer, and anomaly detection. However, generating discrete data is a challenge. This work presents an adversarial training based correlated discrete data (CDD) generation model. It also details an approach for conditional CDD generation. The results of our approach are presented over two datasets; job-seeking candidates skill set (private dataset) and MNIST (public dataset). From quantitative and qualitative analysis of these results, we show that our model performs better as it leverages inherent correlation in the data, than an existing model that overlooks correlation.
期刊:arXiv, 2018年4月3日
网址:
http://www.zhuanzhi.ai/document/262a48fd7a4b081af9e5fc0ced197ec3
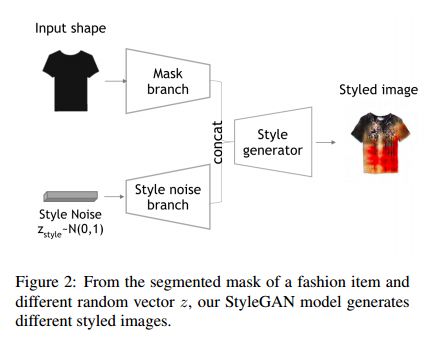
2.DeSIGN: Design Inspiration from Generative Networks(DeSIGN:从生成网络设计灵感)
作者:Othman Sbai,Mohamed Elhoseiny,Antoine Bordes,Yann LeCun,Camille Couprie
机构:New York University
摘要:Can an algorithm create original and compelling fashion designs to serve as an inspirational assistant? To help answer this question, we design and investigate different image generation models associated with different loss functions to boost creativity in fashion generation. The dimensions of our explorations include: (i) different Generative Adversarial Networks architectures that start from noise vectors to generate fashion items, (ii) a new loss function that encourages creativity, and (iii) a generation process following the key elements of fashion design (disentangling shape and texture makers). A key challenge of this study is the evaluation of generated designs and the retrieval of best ones, hence we put together an evaluation protocol associating automatic metrics and human experimental studies that we hope will help ease future research. We show that our proposed creativity loss yields better overall appreciation than the one employed in Creative Adversarial Networks. In the end, about 61% of our images are thought to be created by human designers rather than by a computer while also being considered original per our human subject experiments, and our proposed loss scores the highest compared to existing losses in both novelty and likability.
期刊:arXiv, 2018年4月3日
网址:
http://www.zhuanzhi.ai/document/26337acbfaf4f1079b9999598af6fd9e
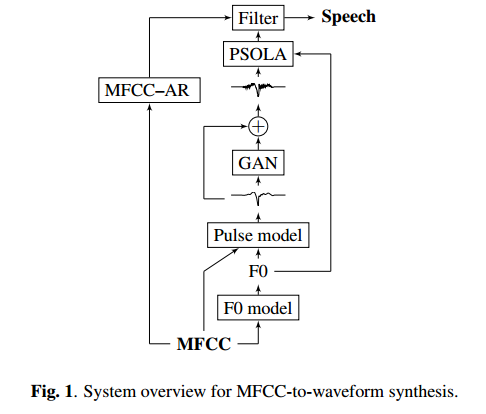
3.Speech waveform synthesis from MFCC sequences with generative adversarial networks(生成对抗网络MFCC序列的语音波形合成)
作者:Lauri Juvela,Bajibabu Bollepalli,Xin Wang,Hirokazu Kameoka,Manu Airaksinen,Junichi Yamagishi,Paavo Alku
机构:Aalto University
摘要:This paper proposes a method for generating speech from filterbank mel frequency cepstral coefficients (MFCC), which are widely used in speech applications, such as ASR, but are generally considered unusable for speech synthesis. First, we predict fundamental frequency and voicing information from MFCCs with an autoregressive recurrent neural net. Second, the spectral envelope information contained in MFCCs is converted to all-pole filters, and a pitch-synchronous excitation model matched to these filters is trained. Finally, we introduce a generative adversarial network -based noise model to add a realistic high-frequency stochastic component to the modeled excitation signal. The results show that high quality speech reconstruction can be obtained, given only MFCC information at test time.
期刊:arXiv, 2018年4月3日
网址:
http://www.zhuanzhi.ai/document/f973871286966f7afe77716cbaf1799c
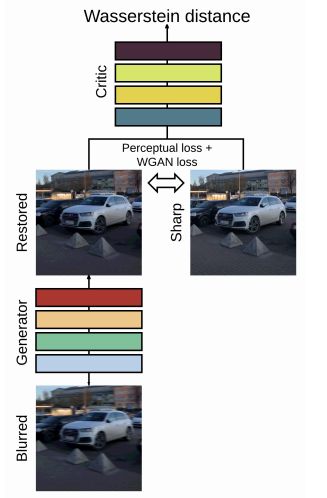
4.DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks(DeblurGAN:使用条件对抗网络进行盲运动去模糊)
作者:Orest Kupyn,Volodymyr Budzan,Mykola Mykhailych,Dmytro Mishkin,Jiri Matas
机构:Ukrainian Catholic University
摘要:We present DeblurGAN, an end-to-end learned method for motion deblurring. The learning is based on a conditional GAN and the content loss . DeblurGAN achieves state-of-the art performance both in the structural similarity measure and visual appearance. The quality of the deblurring model is also evaluated in a novel way on a real-world problem -- object detection on (de-)blurred images. The method is 5 times faster than the closest competitor -- DeepDeblur. We also introduce a novel method for generating synthetic motion blurred images from sharp ones, allowing realistic dataset augmentation. The model, code and the dataset are available at https://github.com/KupynOrest/DeblurGAN
期刊:arXiv, 2018年4月3日
网址:
http://www.zhuanzhi.ai/document/d61a34a94367b712d12810aa00fbadad
5.Generating Diverse and Accurate Visual Captions by Comparative Adversarial Learning(通过比较对抗学习产生丰富精确的视觉描述)
作者:Dianqi Li,Xiaodong He,Qiuyuan Huang,Ming-Ting Sun,Lei Zhang
机构:University of Washington
摘要:We study how to generate captions that are not only accurate in describing an image but also discriminative across different images. The problem is both fundamental and interesting, as most machine-generated captions, despite phenomenal research progresses in the past several years, are expressed in a very monotonic and featureless format. While such captions are normally accurate, they often lack important characteristics in human languages - distinctiveness for each caption and diversity for different images. To address this problem, we propose a novel conditional generative adversarial network for generating diverse captions across images. Instead of estimating the quality of a caption solely on one image, the proposed comparative adversarial learning framework better assesses the quality of captions by comparing a set of captions within the image-caption joint space. By contrasting with human-written captions and image-mismatched captions, the caption generator effectively exploits the inherent characteristics of human languages, and generates more discriminative captions. We show that our proposed network is capable of producing accurate and diverse captions across images.
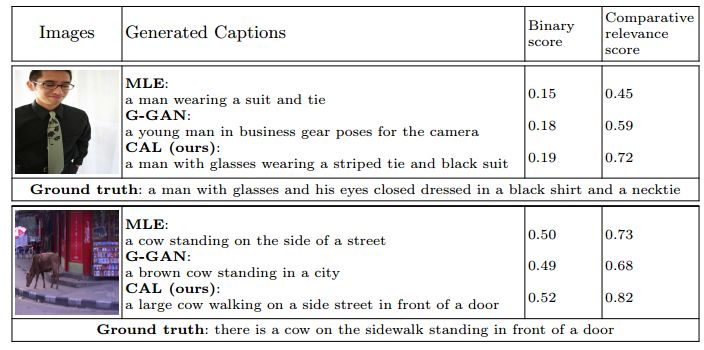
期刊:arXiv, 2018年4月3日
网址:
http://www.zhuanzhi.ai/document/ffa8d8b82eb1fdfd2f65e4ac9351c896
6.High-quality nonparallel voice conversion based on cycle-consistent adversarial network(基于循环一致性对抗网络的高质量非并行语音转换)
作者:Fuming Fang,Junichi Yamagishi,Isao Echizen,Jaime Lorenzo-Trueba
机构:University of Edinburgh
摘要:Although voice conversion (VC) algorithms have achieved remarkable success along with the development of machine learning, superior performance is still difficult to achieve when using nonparallel data. In this paper, we propose using a cycle-consistent adversarial network (CycleGAN) for nonparallel data-based VC training. A CycleGAN is a generative adversarial network (GAN) originally developed for unpaired image-to-image translation. A subjective evaluation of inter-gender conversion demonstrated that the proposed method significantly outperformed a method based on the Merlin open source neural network speech synthesis system (a parallel VC system adapted for our setup) and a GAN-based parallel VC system. This is the first research to show that the performance of a nonparallel VC method can exceed that of state-of-the-art parallel VC methods.
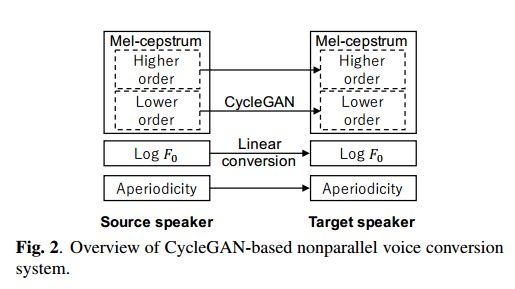
期刊:arXiv, 2018年4月2日
网址:
http://www.zhuanzhi.ai/document/f2f3ad4dd5b1ca04e4d13c1b565826c7
7.Generate To Adapt: Aligning Domains using Generative Adversarial Networks(使用生成对抗网络的对齐方法)
作者:Swami Sankaranarayanan,Yogesh Balaji,Carlos D. Castillo,Rama Chellappa
机构:University of Maryland
摘要:Domain Adaptation is an actively researched problem in Computer Vision. In this work, we propose an approach that leverages unsupervised data to bring the source and target distributions closer in a learned joint feature space. We accomplish this by inducing a symbiotic relationship between the learned embedding and a generative adversarial network. This is in contrast to methods which use the adversarial framework for realistic data generation and retraining deep models with such data. We demonstrate the strength and generality of our approach by performing experiments on three different tasks with varying levels of difficulty: (1) Digit classification (MNIST, SVHN and USPS datasets) (2) Object recognition using OFFICE dataset and (3) Domain adaptation from synthetic to real data. Our method achieves state-of-the art performance in most experimental settings and by far the only GAN-based method that has been shown to work well across different datasets such as OFFICE and DIGITS.
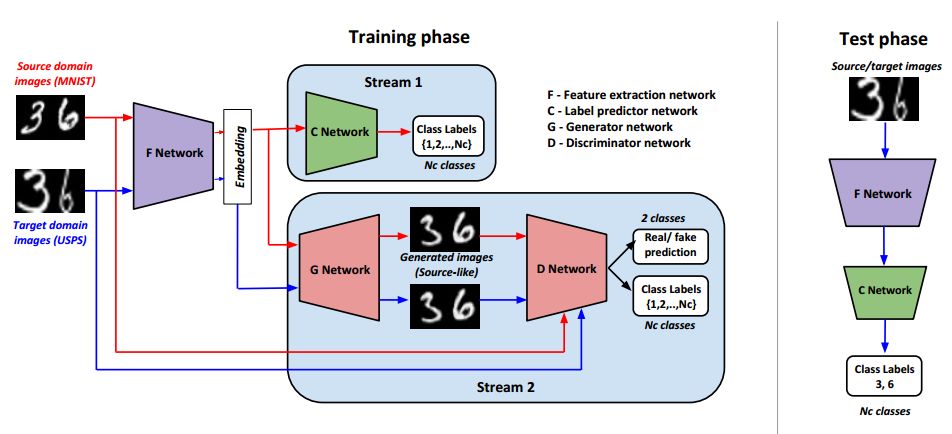
期刊:arXiv, 2018年4月2日
网址:
http://www.zhuanzhi.ai/document/b9ed36da46459a731f442472273f2244
8.Attentive Generative Adversarial Network for Raindrop Removal from a Single Image(基于注意生成对抗网络的去雨滴方法)
作者:Rui Qian,Robby T. Tan,Wenhan Yang,Jiajun Su,Jiaying Liu
机构:Peking University
摘要:Raindrops adhered to a glass window or camera lens can severely hamper the visibility of a background scene and degrade an image considerably. In this paper, we address the problem by visually removing raindrops, and thus transforming a raindrop degraded image into a clean one. The problem is intractable, since first the regions occluded by raindrops are not given. Second, the information about the background scene of the occluded regions is completely lost for most part. To resolve the problem, we apply an attentive generative network using adversarial training. Our main idea is to inject visual attention into both the generative and discriminative networks. During the training, our visual attention learns about raindrop regions and their surroundings. Hence, by injecting this information, the generative network will pay more attention to the raindrop regions and the surrounding structures, and the discriminative network will be able to assess the local consistency of the restored regions. This injection of visual attention to both generative and discriminative networks is the main contribution of this paper. Our experiments show the effectiveness of our approach, which outperforms the state of the art methods quantitatively and qualitatively.
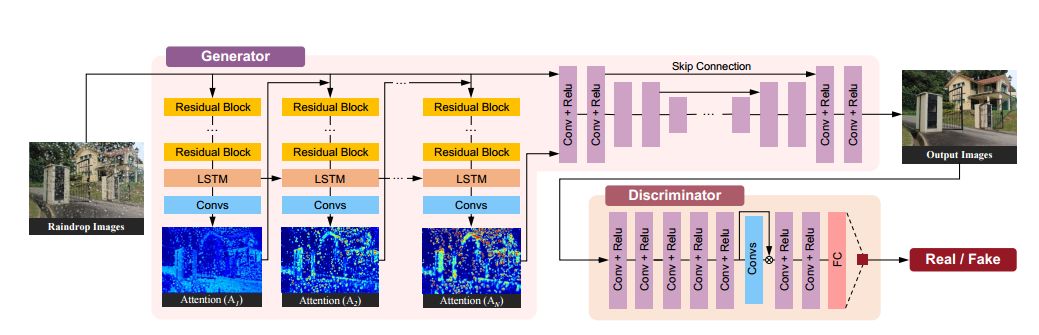
期刊:arXiv, 2018年4月1日
网址:
http://www.zhuanzhi.ai/document/bd9622d0748e6edc3c21e6829514a4dc
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知!


