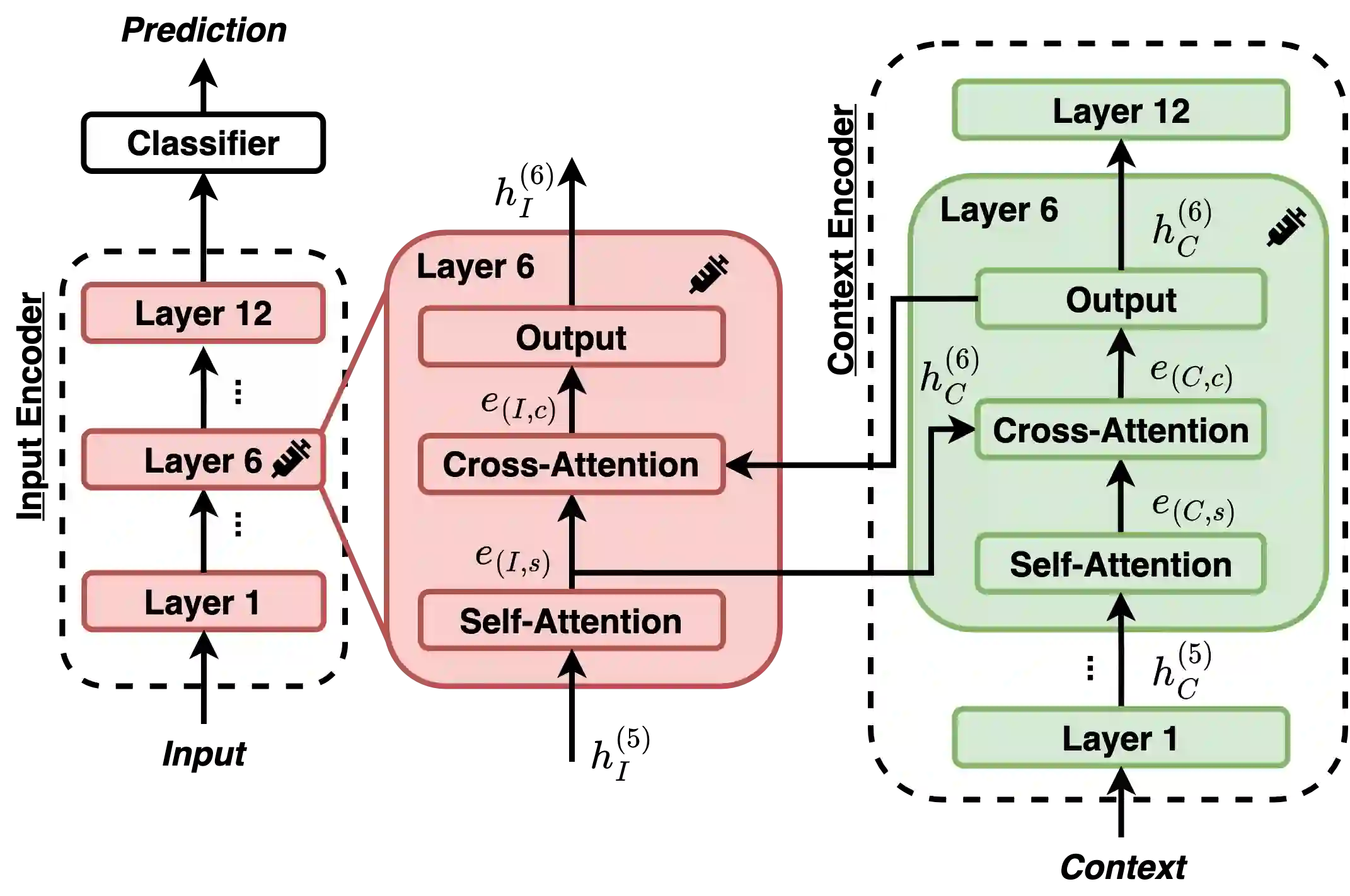
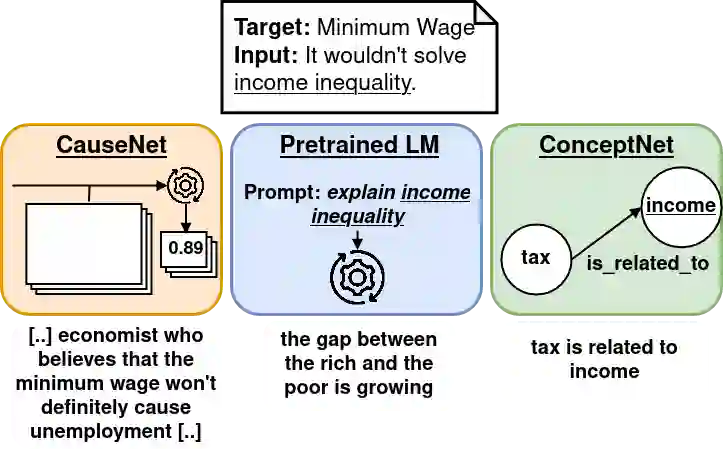
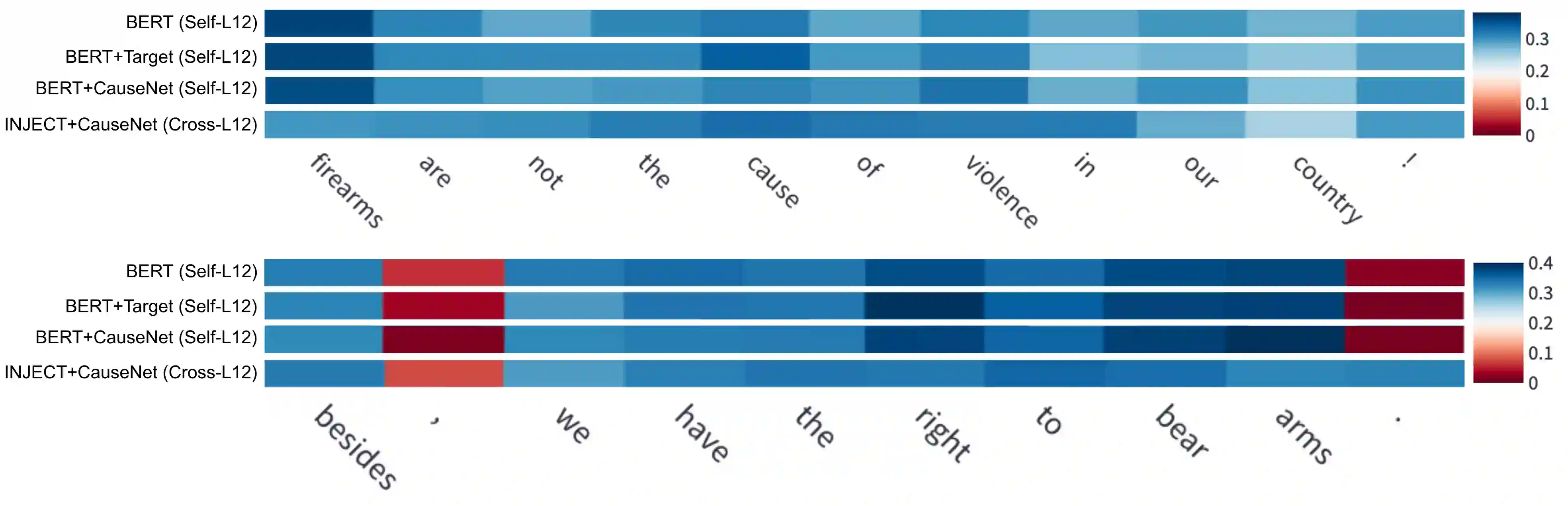
Stance detection deals with the identification of an author's stance towards a target and is applied on various text domains like social media and news. In many cases, inferring the stance is challenging due to insufficient access to contextual information. Complementary context can be found in knowledge bases but integrating the context into pretrained language models is non-trivial due to their graph structure. In contrast, we explore an approach to integrate contextual information as text which aligns better with transformer architectures. Specifically, we train a model consisting of dual encoders which exchange information via cross-attention. This architecture allows for integrating contextual information from heterogeneous sources. We evaluate context extracted from structured knowledge sources and from prompting large language models. Our approach is able to outperform competitive baselines (1.9pp on average) on a large and diverse stance detection benchmark, both (1) in-domain, i.e. for seen targets, and (2) out-of-domain, i.e. for targets unseen during training. Our analysis shows that it is able to regularize for spurious label correlations with target-specific cue words.
翻译:标准检测涉及确定作者对目标的立场,并应用于社交媒体和新闻等多个文本领域。在许多情况下,由于无法充分获取背景信息,推断立场具有挑战性。在知识库中可以找到补充背景,但由于其图形结构,将背景纳入预先培训的语言模型并非三边模式。相反,我们探索一种方法,将背景信息整合为与变异结构更加一致的文本。具体地说,我们培训了一种由双编码器组成的模型,通过交叉注意交流信息。这一结构可以整合来自不同来源的背景信息。我们评估了从结构化知识来源和从促进大型语言模型中获取的背景。我们的方法能够超越大型和多种定位检测基准的竞争基线(平均为1.9pp),这些基准是:(1) 内部的,即对可见目标而言,和(2) 外部的,即对培训过程中看不见的目标而言。我们的分析表明,它能够使标签与具体指标的提示词的虚假相关性正规化。