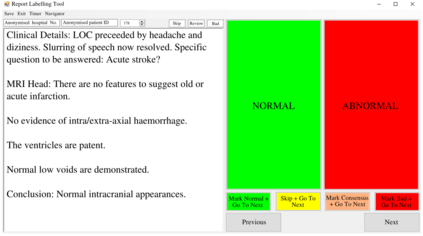
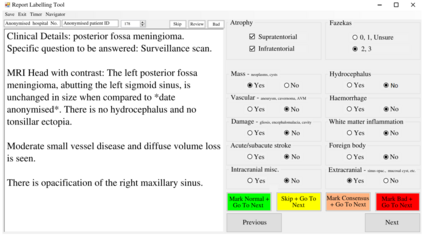
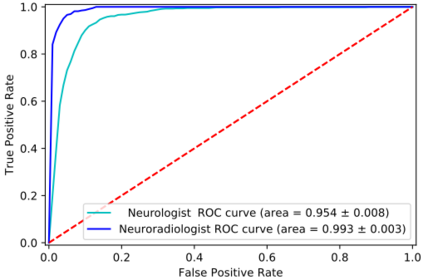
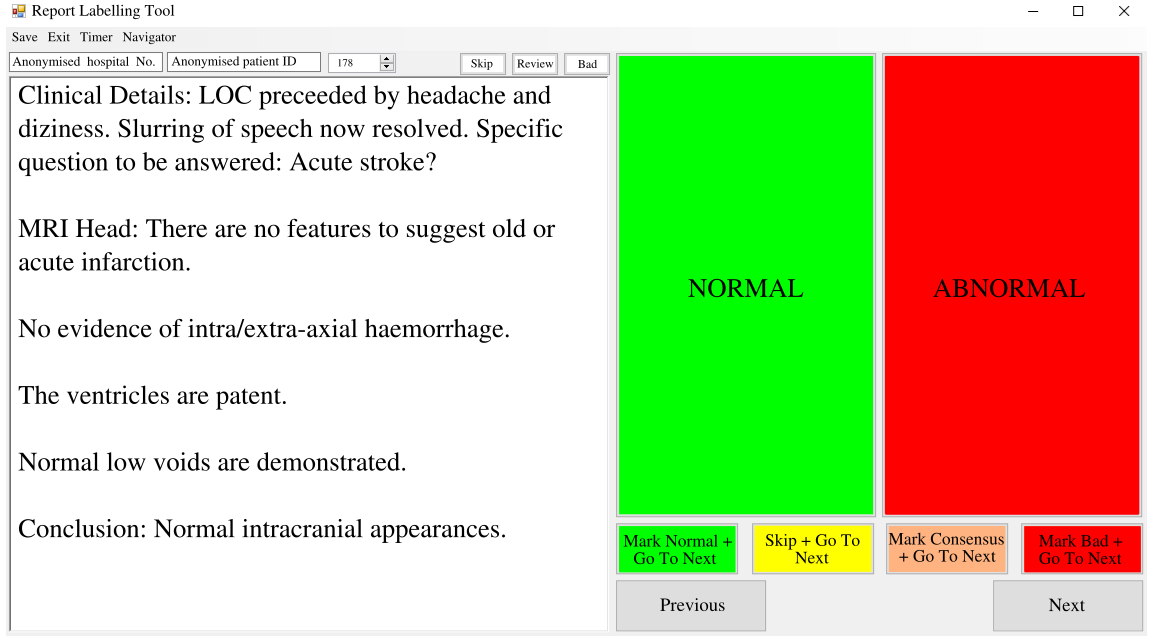
Natural language processing (NLP) shows promise as a means to automate the labelling of hospital-scale neuroradiology magnetic resonance imaging (MRI) datasets for computer vision applications. To date, however, there has been no thorough investigation into the validity of this approach, including determining the accuracy of report labels compared to image labels as well as examining the performance of non-specialist labellers. In this work, we draw on the experience of a team of neuroradiologists who labelled over 5000 MRI neuroradiology reports as part of a project to build a dedicated deep learning-based neuroradiology report classifier. We show that, in our experience, assigning binary labels (i.e. normal vs abnormal) to images from reports alone is highly accurate. In contrast to the binary labels, however, the accuracy of more granular labelling is dependent on the category, and we highlight reasons for this discrepancy. We also show that downstream model performance is reduced when labelling of training reports is performed by a non-specialist. To allow other researchers to accelerate their research, we make our refined abnormality definitions and labelling rules available, as well as our easy-to-use radiology report labelling app which helps streamline this process.
翻译:自然语言处理(NLP)显示有希望将医院规模神经放射磁共振成像(MRI)数据集的标签自动化,用于计算机视觉应用。然而,迄今为止,还没有对这一方法的有效性进行彻底调查,包括确定报告标签与图像标签的准确性,以及检查非专业标签标签的性能。在这项工作中,我们吸取一个神经放射学家团队的经验,该团队将5,000多份MRI神经放射学报告贴上标签,作为建设专门的深层次学习神经放射学报告分类器项目的一部分。我们表明,根据我们的经验,单从报告中分配的二进制标签(即正常与异常)非常准确。然而,与二进制标签相比,更多颗粒标签的准确性取决于分类,我们强调这一差异的原因。我们还表明,当非专业工作者对培训报告进行标签时,下游模式性表现会降低。为了使其他研究人员能够加快他们的研究,我们将我们精细的异常定义和标签规则(即正常与异常)分配给报告本身是高度准确的。然而,与二进封标签的标签则取决于该类别,更多的颗粒标签的准确性取决于该类别,我们能够简化的辐射的标签,从而简化的标签,从而简化了我们的辐射标签作为应用报告。