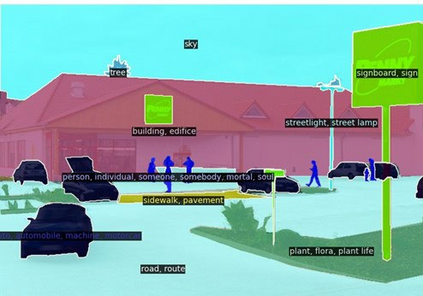
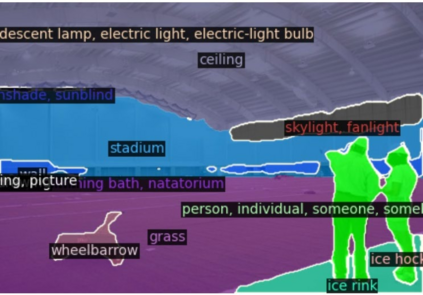
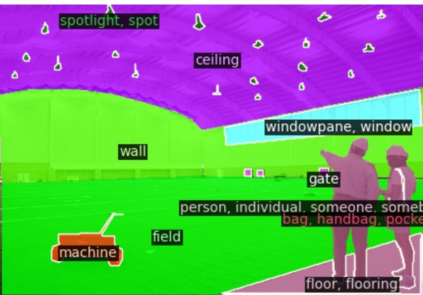
This paper presents a new framework for open-vocabulary semantic segmentation with the pre-trained vision-language model, named Side Adapter Network (SAN). Our approach models the semantic segmentation task as a region recognition problem. A side network is attached to a frozen CLIP model with two branches: one for predicting mask proposals, and the other for predicting attention bias which is applied in the CLIP model to recognize the class of masks. This decoupled design has the benefit CLIP in recognizing the class of mask proposals. Since the attached side network can reuse CLIP features, it can be very light. In addition, the entire network can be trained end-to-end, allowing the side network to be adapted to the frozen CLIP model, which makes the predicted mask proposals CLIP-aware. Our approach is fast, accurate, and only adds a few additional trainable parameters. We evaluate our approach on multiple semantic segmentation benchmarks. Our method significantly outperforms other counterparts, with up to 18 times fewer trainable parameters and 19 times faster inference speed. We hope our approach will serve as a solid baseline and help ease future research in open-vocabulary semantic segmentation. The code will be available at https://github.com/MendelXu/SAN.
翻译:本文为开放式词汇语义分解提供了一个新的框架, 包括预先训练的视觉语言模型, 名为 Side Defer 网络( SAN ) 。 我们的方法模型将语义分解任务作为区域识别问题来模拟。 一个侧网络附属于一个冻结的 CLIP 模式, 有两个分支: 一个用于预测遮罩建议, 另一个用于预测关注偏差, 在 CLIP 模式中用于识别面具类别。 这个分解的设计具有CLIP 承认面具建议类别的好处 。 由于附加的侧网络可以再利用 CLIP 功能, 它可能非常轻。 此外, 整个网络可以被训练成终端到终端, 使侧网络能够适应冷冻的 CLIP 模式, 使预测的 CLIP - 觉悟。 我们的方法是快速的, 准确的, 并且只增加了几个额外的可训练参数。 我们的方法大大超越了其他对应方, 其可训练参数比其他的要少18倍, 并且速度要快19倍 。 我们希望, 我们的边网路方法将会成为坚实的基线和规则。 。